Why Java programmers should use Kotlin (or at least try it)
Door Avisi / sep 2017 / 1 Min

Door Geert Liet / / 6 min

My previous blog post on integration best practices gave some general thoughts on service development. When designing services one of the most important parts is resilience of your services and making sure that failure of one services doesn’t collapse your entire world.
There are several key features of a service which combined determine the fault tolerance of your service. In this blogpost I will explain which features contribute to creating better services.
When designing a service, the service has to have a clear and unique purpose. A service should be able to survive on it’s own and should not have to be altered if some other application or service is changed. Finding the right boundaries is on ongoing process, don’t expect to get it perfect from the start. This means it should be deployable without being dependent on any other services. Communication with other services is an important coupling factor. When limiting the communication with other services, we limit the coupling between these services. The service granularity is always up for debate, I won’t digress to much here, but the the general rule is; don’t start to small.
It is extremely important to version your services in a logical manner where you have a clear and well described version strategy. The way we version software is also very well suited for service versioning. You should be able to know by just looking at the version number of the service if your able to integrate with it. We version our software with major and minor numbers, Like 1.0, where as the 1 is the major version and the 0 being the minor. In this way breaking changes should imply a major number increase. Small changes which do not require client side changes result in a increase of minor number. When needed, an extra field can be added to indicate if a bug fix only release has been done, without features, like 1.0.1.
These version numbers can be incorporated in the service endpoint url, this will make clear which endpoint has which version and makes it possibles for different endpoint versions to exist in parallel. Another option is to use http headers which will contain the version number. Using these techniques makes it possible to have multiple versions of the same endpoint in place. The advantage of having two versions in place is that it makes it possible to release a major change without effecting existing customers. And it allows customers to change when they are ready. Monitoring the usages of these endpoints will allow removal of the service when all customers are migrated.
Two versions of the an entire service is also a possibility but should not be used lightly and certainly not for a long period of time, mainly when migrating or as part of a rollback scenario. The work associated with keeping two service versions alive rarely lives up to its benefits.
It would be even better if there was not need for change at all, this is of-course not realistic but delaying the need for change is. When thinking about connecting to a service it is wise to just read what you need and not more. And do this reading in a generic manner so when a part changes you are not using it does not effect you. In this way you can defer the need to change as long as possible.
When having multiple services in place the end to end call time might exceed the timeout of the first call. Consider the following:
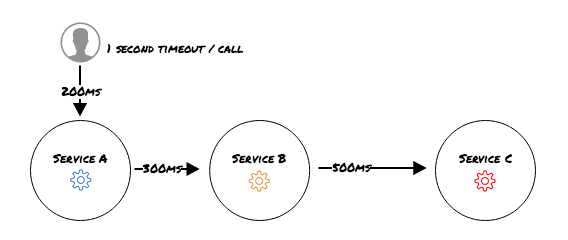
While all individual calls are within the general timeout, the total call time can result in a timeout with the user. So always consider the entire chain when tuning timeouts. Setting the user timeout to a extreme value solves this issue but removes all control and usability.
Let’s assume this time around we have the timeouts setup correctly. And we make a parallel call from service A to B and C:
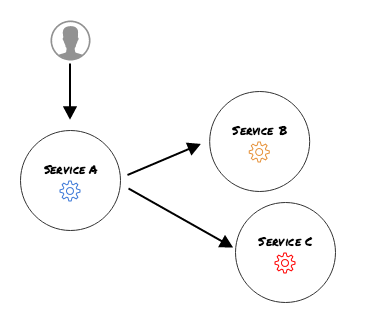
Consider Service A having 1 http pool and Service B is having some trouble. In a while it might by possible that service B used up all pool connections and Service C is never reached again. Sending traffic to an unhealthy service is just making matters worse. You’d really want to give Service B some time to recover and still be able to the call Service C.
There are a few things to help regaining stability in case of failure;
A circuit breaker makes sure that a faulty service is not called again until it recovers. Generally speaking a circuit breaker has 3 states, closed, half-open and open. When in closed state the circuit allows all calls to be made to the target service. If a certain amount of calls fail (usually configurable in an implementation of a circuit breaker) the circuit moves to open state which immediately blocks all outgoing calls to target service. After a (configurable) timeout the circuit breaker move to half open state in which 1 single call is allowed to pass which will determine if the service is ready or not. If the service is not ready the circuit breaker will allow a call again after a certain timeout. If the service is ready the circuit breaker moves to closed state and all service calls proceed as normal.
There are several (open source) libraries available which implement this pattern, like jrugged (comcast) and Hystrix (netflix). Both are available for Java implementations. Hystrix has some nice dash-boarding options to keep track of all our service calls and if you don’t want to use java there is a go implementation of hystrix, hystrix-go.
When talking about service calls, one of the decisions to make is whether the call should be made synchronously or asynchronously. With synchronous communication the calling party expects a reply and blocks until it receives one. Asynchronous communication doesn’t block and does not wait for the operation to complete. Synchronous communication is a lot easier to reason about, everybody understands a call to retrieve data from a service which delivers some result immediately and we know if the operation was successful or not. Asynchronous calls don’t know if the operation was successful immediately or not all. When a service call takes a long time to complete synchronous calling might congest the entire system, in which case an asynchronous call makes more sense.
These two techniques can be used to depict two styles of collaboration, request/response and event based. Where request/response expects an reply on a request, either synchronously or asynchronously and event based works in a reverse order. With reverse order is meant that the party which has something interesting going on, like creating a customer, publishes this and anyone who is interested in this publication is notified.
What does this have to do with service robustness? Indirectly, a lot. When taking the event based road, the services are coupled less tightly which makes it easier to go through change. The publishing party doesn’t even have to know which clients receive his message. Which way to go depends on your situation, just keep all options in mind and choose which style fits in your situation.
Keeping a consistent state for all services involved cannot be done without someform of transaction management. A transaction is a combination of events which should be completed together or not at all. Services and transactions do not differ from normal applications except when these transactions cross service boundaries. Transactions which cross service boundaries are difficult to manage. Two known ways to manage these type of transactions are compensating transactions and distributed transactions.
Compensating transactions can become complicated if there are a lot of nodes to compensate and the compensating that needs to be done is not as simple as just restoring a previous state. If the transaction effects several datastores which all need to be restored accordingly, this has to be done reliable in order to keep a consistent state across the system. So a compensating transaction is a smart piece of software which contains all steps necessary to undo what is done in the original request. These steps do not have to be the exact opposite of the original request, the order in which the compensating is done might also depend on priorities of which part of the system is more important to be consistent.
These steps can fail and it should be possible to retry the failed steps without any side-effects, so the steps itself should be idempotent. If recovering without manual intervention is impossible the system should raise an alert and provide enough information to determine the fault-cause.
Distributed transactions handle multiple events at once which are controlled by a central manager, this central manager keeps track of all these events and will act if something goes wrong. The central manager decides if the entire transaction is valid.Think of an application which reads a message from a message queue and stores, after some processing, the results in a database. For handling these kinds of situations there are several implementations of the XA (eXtended Architecture for DTP) standard available. Like JTA for Java and DTC for .net. Make use of these standards, implementing something similar yourself is not easy and time consuming.
Next step would be testing your services, without testing there is no shipping, right?
Testing ensures that your service implementation is working as intended and stays that way. We will limit our testing to service testing, unit testing and end-to-end are important quality features but there is more than enough information to be found on that topic.
When testing a service on it’s own you’ll need some form of mocking/ stubbing of other services which communicate with the tested service. How you create a service for testing purposes is up to you, there are several free tools available which help building test services. This can be as simple as using json-server (https://github.com/typicode/json-server), or a variant, as a reply service. In this way we can make simple service tests which validate (or not) our service behaviour. Sometimes, for more complicated testing scenarios without hardcoded responses, you want a test service with more capabilities. Think of capabilities as more dynamic responses and better monitorable calls. You might even want to completely replicate a service which would otherwise not be available, this can be useful when connecting to legacy services or third-party services.
Knowing what is happening in your service and between services is extremely important for your well deserved rest after a production deployment. Monitoring the CPU, memory, IO etc. is common practice, we need to know if any of these technical parameters are not in expected ranges so we can send out alerts and act accordingly. This can be done with Nagios, Sensu or Zabbix or some similar tool. Combining this checks with service call times and expected response codes from fixed endpoints covers most of the technical monitoring. Is this enough to make sure our service is doing what we build it for? Probably not. We need to monitor the services functionality as well. Tracking error rates and outgoing calls add to the overall health picture of your service.
Logging this data to a central location is imperative, make sure that your service sticks to logging guidelines of your company or else it will make aggregation very difficult. Especially when multiple services are involved the need for knowing that a event which traverses through multiple services results in an expected outcome.
| Non-technical blogs
Door Geert Liet / okt 2024