Integration best practices - thoughts on ESB and SOA
Door Geert Liet / jan 2016 / 1 Min

Door Niek Knuiman / / 3 min

While implementing messaging in a microservice architecture, I was asking myself questions such as:
After everything had been implemented correctly, a new set of underlying challenges arose:
These challenges stem from introducing a third component to a simple A to B connection, whereby you create additional separate locations where something can go wrong. Though it does not mean that the chance of entering a failure flow is higher, there is more logic involved to gracefully respond when an error occurs.
In this blog, I will present some challenges related to error handling and give possible solutions when it comes to choosing an implementation that suits your needs.
Note: In the examples below, I am using the NATS Messaging System. It is known for its simplistic implementation of the publish-subscribe model without any distracting bells and whistles.
I'll start with a comparison between the traditional synchronous communication and its asynchronous counterpart.
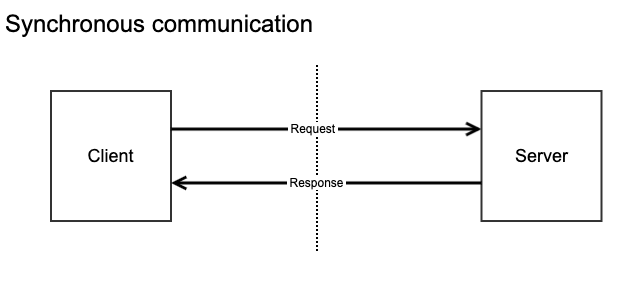 In In this very simple example, a client sends a synchronous message with three possible outcomes:
In In this very simple example, a client sends a synchronous message with three possible outcomes:
For the sake of simplicity, I won't include errors that can occur at the client. Messaging has no implication for handling client-side errors. In all three scenarios, the client knows that something went wrong and can act accordingly so the message is not lost. If changes were made while processing the request on the server, it's the responsibility of the server to rollback any changes made.

In this next example, a producer sends an asynchronous message to the NATS-server which sends it along to the consumer. This adds one additional scenario to the mix of possible outcomes:
In scenario 3, the NATS-server just retries until a consumer is available, or until the message is no longer relevant. In scenario 4, the producer can act in the same manner as our first example. Scenario 2 is a bit more complex. The NATS-server has only two options: retry or drop the message. The NATS-server only knows two things; there was no network error while sending the message to the consumer, as was the case in scenario 3, and the consumer did not acknowledge (ACK) the sent message. Let's try solving this issue in the next chapter.
We can let the NATS-server retry forever. This means that the consumer should be configured in such a way that it acknowledges the message after the least amount of logic. For example, you can do this by using a database queue on the consumer-side. If there is an error while saving, don't acknowledge and let the NATS-server try again. While this transfers the problem to the consumer, it does give more flexibility about how and when you retry. In addition, incorrect messages can be inspected and even repaired manually more easily.
This strategy can be dangerous because it could contaminate that NATS channel with multiple non-processable messages that cannot be saved to the database. This could slow down throughput but after fixing the problem, no messages should be lost. If the problem is at the producer-side, the existing messages can be fixed manually by accessing the database. If the problem is at the consumer-side, no additional actions are required. It is important to note that, depending on the Max-In-Flight setting, the extra processing time can hold up the next message from being sent on the same channel.
Pick this option if losing messages has larger consequences than the pain it will cause to run a recovery process for all unprocessed messages.
We can also have the NATS-server retry a few times and, if unsuccessful, consider the message lost after that. This means that if the content of the message created the problem, and not the service itself, it won't halt a complete channel from receiving messages. With this strategy, you can abuse the NATS-server retry by processing the request before acknowledging it. This saves development time by implementing a database queue while using a 'best effort' strategy for saving messages.
Choose this option if the time the message is relevant is short and of lesser importance. Also, take the message processing time into consideration. Longer processing can cause unnecessary retrying, making this strategy less optimal.
There is also a more development-heavy option that expands upon the second solution. By determining which exceptions would never benefit from a retry and acknowledging only those, you reduce retries. By this logic, you should acknowledge parsing exceptions. They will break again for the next retry, so by acknowledging them there is less traffic and work. Don't forget to log or even audit the error and its context. An Out-Of-Memory exception might be recoverable. The consumer service can reboot or maybe another instance of the same service can process the message.
It does take a lot of time to write and maintain the logic for determining a retry but this allows the server to retry longer because of the higher certainty that the messages can be automatically recovered. Make sure only to retry a message a limited amount of times when including (partial) business logic before the acknowledgment to prevent your complete message chain from locking up though!
Solution 1 is your best option if it is crucial that the message is never lost. Every product owner will tell you that no message can ever be lost. In reality, retrying indefinitely won't be the answer for a lot of applications.
Solution 2 is more practical to develop and to maintain. However, it may not be the most reliable or performant option.
The smart thing to do is to pick a solution between the two extremes. Analyze the costs and benefits. Decide how often you retry and how far you want to move towards solution 3, based on the outcome of your analysis. Finally, implement good logging and metrics and find your own sweet spot.
| Software Development
Door Niek Knuiman / okt 2024