Muziek classificeren door Machine Learning met Rust
Door Kevin Schomper / jun 2022 / 1 Min

Door Esra Bakker / / 6 min
.jpg?length=800&name=Tekengebied%201-100%20(5).jpg)
Recently a lot of companies (Avisi included) have been researching and implementing natural language processing solutions. Think, for example, about a chatbot that helps to provide customer service; a virtual assistant to verbally delegate tasks to; your email's spam filter; a spellchecker; or a digital translator. It turns out that to annotate and prepare the data for processing, you need a lot of resources, specifically time. As we, at any given time, have multiple projects running within Avisi Labs, time is a limited resource. Thus, we are always interested in techniques that can reduce the amount of time we have to spend on annotating training data and still produce an effective model. Active learning is a technique that aims to use the training data more efficiently and thus reduce the number of samples that are needed to train the model.
 Source: Telus International
Source: Telus International
Active learning is considered a semi-supervised machine learning technique that queries a teacher or some other information source to annotate specific samples. In active learning we use the model itself to select samples that are useful for improving performance. For example, we could select samples for which the model is least confident about labeling, with the idea that when similar samples are encountered in the future the model will perform better. After the annotated samples are provided the model can be retrained. Basically, at each iteration we use the trained model to select new samples to label and then retrain the model with these newly labelled samples being added.
Three main configurations are commonly researched in active learning:
Figure 1. visualization of the strategies
To create an active learning based model we need three components, an initialization strategy, a query strategy, and optionally a stopping criterion. The initialization strategy refers to the initial training approach prior to actively selecting samples. Generally some random samples are selected and used to train the model. The query strategy defines the informativeness measure used to pick the samples for each iteration. The stopping criteria specifies when to stop selecting new samples. In our work we are primarily interested in which query strategy we should use to best improve our models.
There are many different possible query strategies but we've looked at the following strategies:
The library we used has implementations of many more query strategies, which you can find here.
As active learning is becoming more and more popular, there are several packages in Python that provide implementations. One of these packages is small-text which provides active learning specifically for text classification. This library offers a straightforward way to mix and match different strategies and classifiers. They even offer ways to mix their framework with PyTorch and Scikit-learn or Transformers classifiers.
We'll run through an example of how to implement the active learning models from small-text below. The data we'll be working with is a Kaggle music classification dataset, which consists of song lyrics and their label. The dataset consists of over 50,000 songs that each have a binary label. A 0 correlates to rap lyrics and a 1 correlates to pop lyrics. As the lyrics are natural language, we'll need to do some preprocessing before we can feed it into the model for training.
We start by loading the data, which comes in the form of a CSV-file, and use a pandas dataframe to load it in. Then we split the dataset into a training and a test set on which we train and fit a Term Frequency-Inverse Document Frequency (TF-IDF) vectorizer. This vectorizer encodes the text into tokens which is a format the model can use. Each token maps to a specific word or part of a word. An added feature of this vectorizer is that it weighs the tokens on importance. This is determined by how often a word occurs in a document vs how many documents contain that word. This allows words such as 'the', which occur many times in a document but are also present in many documents, to carry less weight than words that actually hold meaningful information about the contents of the document. Lastly, we turn it into a SklearnDataset for both the training and the test data.
dataframe = pd.read_csv(filename, sep=',')
def preprocess_data(dataframe):
X = dataframe['lyric'].to_list()
y = dataframe['class'].to_numpy()
x_train_split, x_test_split, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=17)
vectorizer = TfidfVectorizer(stop_words='english')
x_train = normalize(vectorizer.fit_transform(x_train_split))
x_test = normalize(vectorizer.transform(x_test_split))
return SklearnDataset(x_train, y_train), SklearnDataset(x_test, y_test)
train, test = preprocess_data(dataframe)
When we've processed our data we can define the method that will actually perform the active learning process. This method iteratively selects samples to query and subsequently updates the labels of these samples. We'll also be computing the accuracy of the model on the training and test data each iteration so we can store this to use for plotting later.
def perform_active_learning(active_learner, train, indices_labeled, test, num_iterations, num_samples):
"""
This is the main loop in which we perform num_iterations of active learning.
During each iteration num_samples samples are queried and then updated.
The update step reveals the true label to the active learner, i.e. this is a simulation,
but in a real scenario the user input would be passed to the update function.
"""
# Set up array to track accuracy scores
train_accuracy = []
test_accuracy = []
# Perform num_iterations of active learning...
for i in range(num_iterations):
# ...where each iteration consists of labelling num_samples
indices_queried = active_learner.query(num_samples=num_samples)
# Simulate user interaction here. Replace this for real-world usage.
y = train.y[indices_queried]
# Return the labels for the current query to the active learner.
active_learner.update(y)
indices_labeled = np.concatenate([indices_queried, indices_labeled])
print('Iteration #{:d} ({} samples)'.format(i, len(indices_labeled)))
train_acc, test_acc = evaluate(active_learner, train[indices_labeled], test)
train_accuracy = np.append(train_accuracy, train_acc)
test_accuracy = np.append(test_accuracy, test_acc)
return train_accuracy, test_accuracy
def evaluate(active_learner, train, test):
y_pred = active_learner.classifier.predict(train)
y_pred_test = active_learner.classifier.predict(test)
f1_score_train = f1_score(y_pred, train.y, average='micro')
f1_score_test = f1_score(y_pred_test, test.y, average='micro')
print('Train accuracy: {:.2f}'.format(f1_score_train))
print('Test accuracy: {:.2f}'.format(f1_score_test))
print('---')
return f1_score_train, f1_score_test
The last component that we need to write is an implementation for the initialization strategy. For this we simply pick some random samples from the dataset, making sure that we have samples for both categories. To query samples from the unlabelled part of the dataset the model is supplied with the full training set and it keeps track of the samples that have been annotated. This means that for the initialization we only have to produce the indexes and respective labels of the samples we'd like to update in the model.
def initialize_strategy(active_learner, y_train):
# Initialize the model. This is required for model-based query strategies.
indices_pos_label = np.where(y_train == 1)[0]
indices_neg_label = np.where(y_train == 0)[0]
indices_initial = np.concatenate([np.random.choice(indices_pos_label, 100, replace=False),
np.random.choice(indices_neg_label, 100, replace=False)],
dtype=int)
active_learner.initialize_data(indices_initial, y_train[indices_initial])
return indices_initial
Now that we've prepared our puzzle pieces it's time to piece them together. We train a new classifier every generation. For this we use a ClassifierFactory which generates a new classifier object and provides it with the appropriate arguments. For the query strategy we start out by using random sampling, but as mentioned above we have looked at more sampling methods such as least confidence and entropy sampling.
You can find the full code in our repository.
num_classes = 2
# Active learning parameters
clf_template = ConfidenceEnhancedLinearSVC()
clf_factory = SklearnClassifierFactory(clf_template, num_classes)
query_strategy = RandomSampling()
# Active learner
active_learner = PoolBasedActiveLearner(clf_factory, query_strategy, train)
labeled_indices = initialization_strategy(active_learner, train.y)
try:
perform_active_learning(active_learner, train, labeled_indices, test, num_iterations=30, num_samples=1000)
except PoolExhaustedException:
print('Error! Not enough samples left to handle the query.')
except EmptyPoolException:
print('Error! No more samples left. (Unlabeled pool is empty)')
So now that we've trained our models, how do they compare against one another? In figure 2 below we can see that all models we've tested seem to score an accuracy of around 75%. For a model that has only trained for 30 iterations on about half of the dataset, with out-of-the-box strategies, being significantly above the guessing-level is a good result. As we can see from the confusion matrices below (see figure 3) the models still make mistakes now and then, which is not that surprising looking at the actual data itself (see figure 4) which is very hard to classify for us as humans as well. A study has shown that humans err in repetitive tasks like classifying documents as well and can fail to accurately identify as much as 10%(1). We think that the mistakes come from the lyrics that seem to be taken from the chorus, which between pop songs and rap songs are generally more similar.
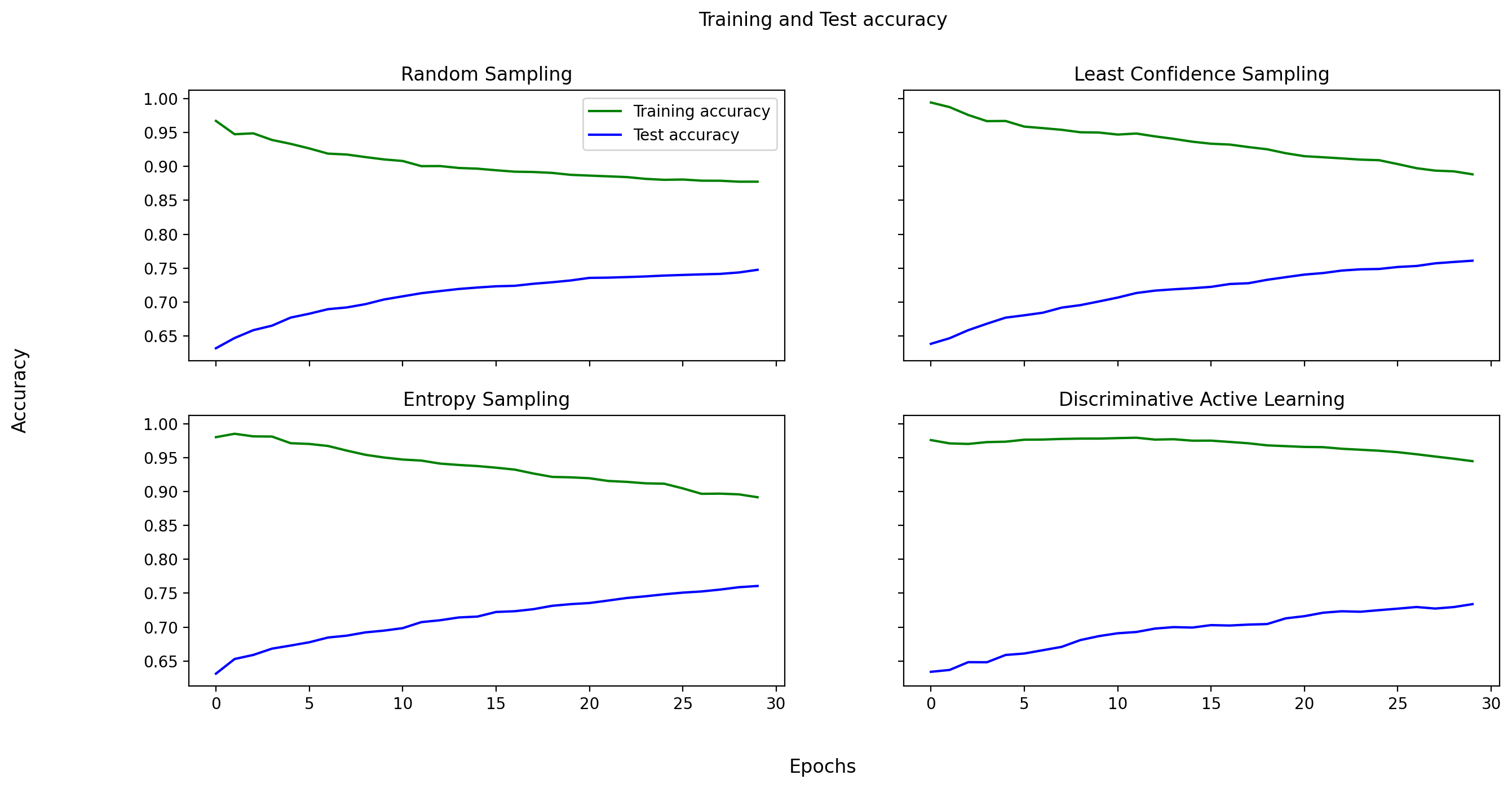 Figure 2: Train and test accuracies for the model.
Figure 2: Train and test accuracies for the model.
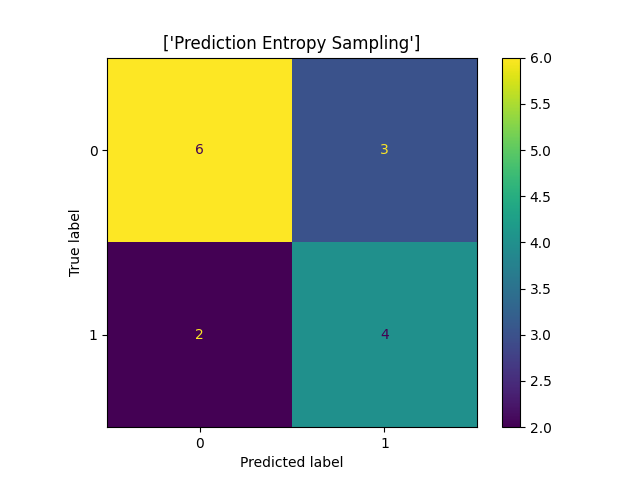
Figure 3: Confusion matrices for the prediction of the
labels for the first 15 samples of the test dataset
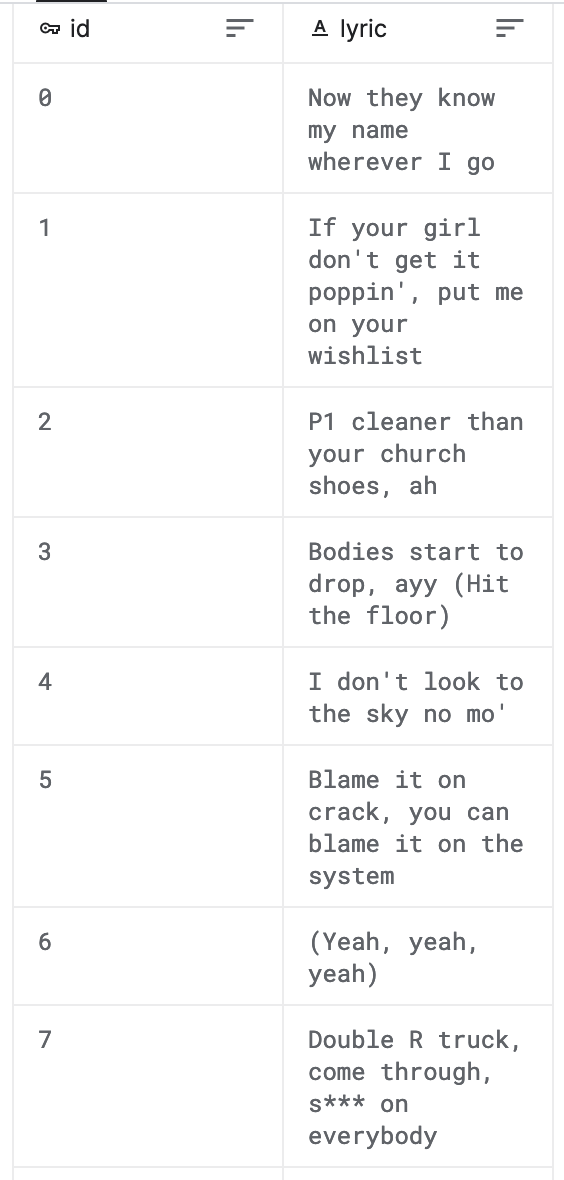 Figure 4: Test dataset contents
Figure 4: Test dataset contents
If we were to pick or write a query strategy that would fit our data better and introduce a more appropriate initialization strategy, we could further improve the model's accuracy. As our goal is to be able to classify data in categories that lie quite close to each other we might also find data that represents each category better than the dataset we used now. For example, we found that the method to pick lyrics from each song was done quite randomly. Some lyrics are taken from the chorus while others were taken from the verse and this introduces a significant variety within each category. So a more consistent strategy to acquire data for an NLP application is likely to influence the accuracy of the model trained on it.
Active learning is definitely an interesting technique, and we're hoping to use it for more NLP projects in the future. Our next step with active learning is going to involve using this technique in combination with a Named Entity Recognition model to see if we can actually use it in our applications. As we have a ton of data to annotate, it would be beneficial if we can use active learning to drastically reduce the number of samples we have to label.
If you would like to see us share more about this topic, let us know and we would love to keep you updated with our progress. Also, don't forget to check out the video we made about this topic or other topics you might find interesting on our YouTube page.
| Artificial Intelligence
Door Esra Bakker / okt 2024