Problemen bij het trainen van face recognition-models. Zo los je ze op
Door Kevin Schomper / nov 2021 / 1 Min
.jpg)
Door Kevin Schomper / / 5 min
.jpg?length=800&name=Social%20(1).jpg)
Recentelijk is de interesse in high performance programming flink gegroeid binnen Avisi Labs, wij zijn namelijk opzoek naar meer snelheid wanneer we met grote datasets werken bij bijvoorbeeld machine learning. Daarnaast zijn wij altijd bezig met het zoeken naar alternatieven om machine learning buiten Python toe te kunnen passen. Daarom zijn wij nu dan ook bezig met een reeks aan artikelen die programmeertalen op het machine learning vlak bespreken (zie hier de blog over Kotlin).
Rust is een programmeertaal waarin wij allemaal geïnteresseerd zijn omdat wij een halfjaar terug een eerste kijk hebben genomen naar de mogelijkheden rondom machine learning.
Binnen Labs houden wij erg van muziek (wie niet) en is de diversiteit aan muziek die geluisterd wordt erg hoog! Het verschil tussen onze muzieksmaken zouden we zelf samenvatten door genres op te noemen, maar nu zouden wij geen Avisi TechLab zijn als we dat niet aan de hand van wat interessantere data kunnen.
Door een interessante blogpost op Linkedin kwam ik op het idee om verschillende Machine Learning modellen te trainen die onze muzieksmaak categoriseert. Gezien onze groeiende interesse in andere programmeertalen dan Python voor Machine Learning, is dit een mooi startpunt voor ML in Rust.

De functionerende flow van dit project zal zijn als volgt: Spotify trackdata via bovenstaande blogpost data laten exporteren (in de codebase staat een Jupyter notebook die de data wegschrijft naar een Postgresql db), vervolgens de data in Rust inladen en via SmartCore modellen trainen op de dataset.

Binnen het Rust ML-ecosysteem wordt volop ontwikkeld, dit wordt bijgehouden hier en hier). Er zijn packages met connecties naar populaire libraries zoals Tensorflow en Keras, én er zijn manieren om gebruik te maken van de snelheid en safety van Rust via bijvoorbeeld RustaCUDA. Waar ik gebruik van maak om muziek te classificeren zijn de Linfa en SmartCore libraries, dit zijn uitgebreide ML libraries. Ik heb hier meer gebruik gemaakt van de SmartCore libraries, dit komt voornamelijk doordat het Linfas "Dataset" type ervoor zorgt dat er veel dataconversies gedaan moeten worden van de originele ingeladen vector en omdat Linfa ook geen goede classificatiemetrieken aanbiedt om modellen goed te analyseren.
Om het gebruikersgemak van SmartCore aan te tonen zullen meerdere modellen worden gebruikt met verschillende doelen:
Single Classifier modellen zullen worden gebruikt om Kevins en Eriks muzieksmaak te categoriseren:
Multi Classifier a.d.h.v. clustering zal worden gebruikt om alle 7 playlists te categoriseren:
Er zijn 7 playlists gebruikt van 7 verschillende personen, zie de figuur hieronder, in onze dataset zijn 100 nummers opgenomen uit een door hun ingestuurde playlist (voor het verkrijgen van de Spotify data zie deze blogpost).
Kevin:
Eline:
Esra:
Erik:
Marcel:
Jordi:
Albert:
In deze dataset zitten de volgende datapunten. Deze zijn verkregen uit de Spotify API.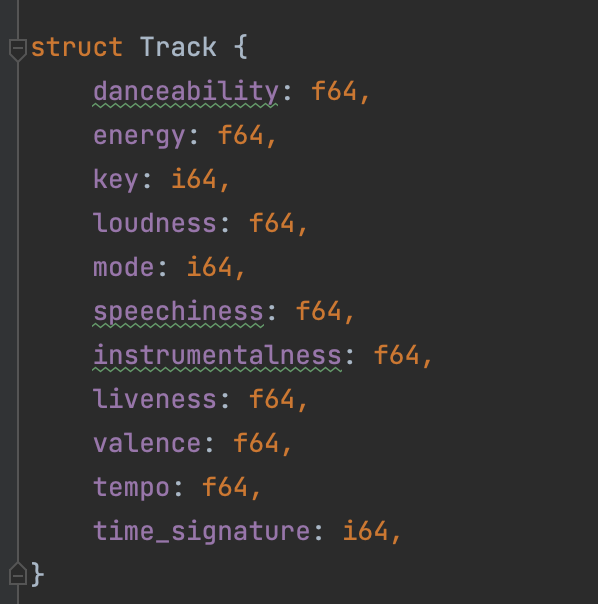
Deze datapunten samen proberen de muziek zo goed mogelijk te beschrijven. Alleen is muziek dynamisch wat betekent dat een nummer dat van tempo veranderd minder word beschreven door het tempo datapunt. In het volgende hoofdstuk kijken we of Machine Learning-modellen genoeg verschil vinden binnen deze tracks voor classificatie.
Mijn verwachting is dat de modellen goed de verschillen vinden tussen de verschillende playlists:
.png?width=577&name=6%20(1).png)
Het trainen van verschillende modellen is voor alle modellen veelal gelijk. Zie https://github.com/AvisiLabs/rustml voor de Codebase.
De belangrijkste code voor het trainen van het decision tree model is hieronder te zien:
fn train_dt() -> DecisionTreeClassifier {
let (dataset, y) = get_dataset_kevin();
let records =
Array::from_shape_vec(dataset.raw_dim(), dataset.iter().cloned().collect()).unwrap();
let x = DenseMatrix::from_array(
y.len(),
records.len_of(Axis(1)),
dataset.as_slice().unwrap(),
);
let (x_train, x_test, y_train, y_test) = train_test_split(&x, &y, 0.2, true);
let dt = DecisionTreeClassifier::fit(
&x_train,
&y_train,
DecisionTreeClassifierParameters::default(),
)
.unwrap();
// For performance metrics
let predictions = dt.predict(&x_test).unwrap();
let predict_train = dt.predict(&x_train).unwrap();
let data = accuracy(&y_test, &predictions);
let compare = accuracy(&y_train, &predict_train);
let performance = vec![(data * 100.0f64) as i32, (compare * 100.0f64) as i32];
println!("{:?}", performance);
performance_graph("dt_accuracy.svg", "accuracy", performance)
.expect("Write of accuracy graph was not successful");
let data = f1(&y_test, &predictions, 1.0);
let compare = f1(&y_train, &predict_train, 1.0);
let performance = vec![(data * 100.0f64) as i32, (compare * 100.0f64) as i32];
println!("{:?}", performance);
performance_graph("dt_f1.svg", "F1 Score", performance)
.expect("Write of f1 graph was not successful");
dt
}
Deze code lijkt veel op hoe Sklearn werkt in Python, dit is dan ook de library waarop SmartCore is gebaseerd. Het decision tree-model fitten we op onze dataset en vervolgens kunnen we direct predicties maken en classificatiemetrieken opvragen over de functionering van het model. De classificatiemetrieken voor de verschillende modellen zijn hieronder te zien.
Laten we kijken naar de statistieken van de classificatie-modellen. In de figuren hieronder is te zien dat het decision treemodel en het linear regressionmodel erg goed presteren op de dataset. Ik ben zelf positief verrast met de performance van deze modellen, ze presteren binnen de test en trainingset erg accuraat en kunnen duidelijk verschil vinden tussen de muziek van mij en Erik. bij het valideren door een derde dataset aan te leveren hieronder valt te lezen of je daadwerkelijk ook muziek zou kunnen aanraden aan iemand met een van deze modellen.



Voor het clustering model, is het duidelijk dat de completeness niet erg hoog is (0.148), clusteren is dus duidelijk niet erg goed te doen op onze groepen.
Hierboven zie je dat de modellen zijn getraind. Je zou nu denken dat de modellen goed functioneren, toch? Laten we kijken naar hoe de modellen daadwerkelijk presteren op nieuwe data.
Hoe presteren deze modellen dan op daadwerkelijk nieuwe data? Om hierachter te komen, heb ik voor de verschillende modellen een validatie-dataset overgelaten.
De playlists die ik gebruikt heb voor de validatie van de single classifiers staan hieronder.
Kevin
Erik
Hieronder staan zeven tracks die gebruikt zijn als validatie voor het Kmeans-model.
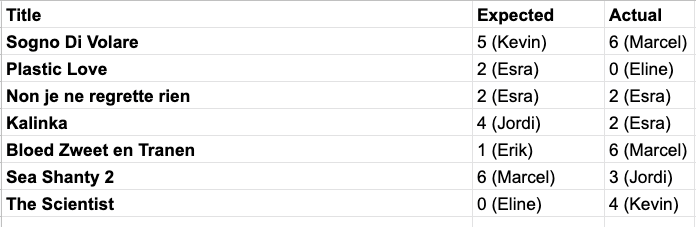
Deze dataset gaat vervolgens door de verschillende modellen, in de hoop dat de correcte persoon wordt teruggegeven door het model.
Het Random Forest-model en het K-Nearest Neighbors-model presteren goed in het separeren en teruggeven van verwachtte categorieën rond Erik en Kevins muziek. Dit komt waarschijnlijk doordat er zo'n groot verschil zit tussen de twee smaken.
Voor het Kmeans model was deze validatieset pittig. De nieuwe muziek is geboxed in (in onze optiek) dezelfde genres als onze originele dataset, maar dat betekent voor dit model nog niet dat de correcte predicties worden gemaakt. Doorde input dataset een factor van 5-10x groter te maken zal het model betere resultaten geven.
Rust staat bekend als een snelle programmeertaal. Al helemaal in vergelijking met Python! Het trainen van deze modellen is dan ook sneller dan een Sklearn-model. Hierbij is het wel zo dat de snelheid van Rust voornamelijk komt bij het ophalen en bewerken van data, het analyseren van de performance, het snel kunnen trainen van een nieuw model en het plotten van de performance, want de meeste Sklearn-modellen zijn ook geschreven in een snelle programmeertaal op de achtergrond, zie Sklearns-documentatie voor meer info.
Wat SmartCore ook aanbiedt is de middelen om deze modellen te testen aan de hand van voorbeelddatasets en natuurlijk kunnen de verschillende modellen worden opgeslagen via de Serde library.
Helaas loopt SmartCore als library nog flink achter. Dat doet het op de verschillende aangeboden modellen, performance metrieken en utilities die Sklearn aanbied. Daarom is het wijs om te controleren of wat jij denkt nodig te hebben al bestaat in SmartCore. Anders is het slimmer om te werken met het meer feature complete Sklearn.

Dat de muziek tussen twee personen uit elkaar gehouden kan worden was leuk om te bevinden, en dat er ook genoeg informatie in de datastructuur van Spotify zit om muziek te classificeren. Rust toont zich weer een valide kandidaat in mijn ogen met hetgroter wordende systeem van packages rondom AI. Toch moeten er nog zeker stappen worden gezet om de volledige mogelijkheden van Sklearn en Tensorflow aan te bieden binnen Rust.
Voor nu is Rust daarom meer geschikt voor ML-ontwikkelaars die al duidelijk hebben welk model zij gaan gebruiken voor hun dataset en deze na het trainen direct willen draaien in productie. Daarnaast is ook meer begrip nodig van ML en programmeren in vergelijking met Python. Dit komt door de mindere ondersteuning en technischere implementatie van de libraries in Rust.
Ben je gemotiveerd om met ML of Rust aan de slag te gaan? kijk dan bij een van deze linkjes:
Voor classificatie gebaseerd op de gebruikte frequenties binnen muziek komt ook nog binnenkort een blog van Marcel van Heerdt. Dat gaat over spectogrammen en is wel een mooie oplossing om muziek te classificeren die niet op Spotify staat.
| Artificial Intelligence
Door Kevin Schomper / okt 2024