Devoxx: Kotlin under the hood
Door Avisi / dec 2019 / 1 Min

Door Marcel van Heerdt / / 8 min
.jpg?length=800&name=Tekengebied%201-100%20(3).jpg)
Bij het ontwikkelen van AI-oplossingen loop je weleens tegen uitdagingen aan. Een uitdaging waar wij tegenaan zijn gelopen is de programmeertaal Python. Deze programmeertaal voelt alsof het bedoeld is om mee te experimenteren, maar zodra je je applicatie robuuster wil maken zul je al snel naar een andere programmeertaal uitwijken. Zo gebruiken wij dagelijks Kotlin, vanwege het ontwikkelgemak en de leesbaarheid.
Omdat Python geschikt is voor het experimenteren met data, zijn er veel libraries voor beschikbaar. Hieronder vallen allerlei AI-libraries, waaronder voor deep learning. Het AI-ecosysteem van de JVM is (nog) niet groot, waardoor wij verrast waren toen Jetbrains met KotlinDL kwam. Ben jij ook benieuwd naar hoe je KotlinDL kunt gebruiken om deep learning-modellen te maken? En biedt het wel alle features die je nodig hebt als je met deep learning aan de slag wil in Kotlin? Lees dan vooral verder! In deze blog neem ik je mee in de verschillende aspecten van KotlinDL.
Alle volledige code-voorbeelden kun je vinden in de repository op GitHub.
KotlinDL is een high-level API voor deep learning, geschreven in Kotlin en geïnspireerd door Keras. Je hoeft dus geen precieze kennis te hebben van hoe het model op de achtergrond wordt opgebouwd. Je hoeft alleen te weten welke layers je in je model nodig hebt en hoe je die wil configureren. KotlinDL gebruikt onder water TensorFlow voor het maken van modellen. Ook wordt ONNX ondersteund voor het inladen van bestaande modellen.
Als je niet bekend bent met Python, kun je tegen een steile leercurve aanlopen bij het gebruik van Keras. Het meeste voordeel haal je dan ook uit KotlinDL als je in je normale werkzaamheden al werkt met JVM talen, in het bijzonder met Kotlin zelf. De API die KotlinDL aanbiedt, komt overeen met die van andere Kotlin-libraries. Hierdoor voel je je er snel bekend mee en loop je niet tegen een leercurve aan.
KotlinDL kun je gemakkelijk toevoegen aan je project door gebruik te maken van onderstaande dependencies in Gradle. Deze dependencies gelden ook voor Maven. Voor de basisfunctionaliteiten heb je alleen de eerste dependency nodig. De tweede heb je nodig voor ONNX-modellen en de laatste voor visualisaties van je modellen.
implementation("org.jetbrains.kotlinx:kotlin-deeplearning-api:0.3.0")
implementation("org.jetbrains.kotlinx:kotlin-deeplearning-onnx:0.3.0")
implementation("org.jetbrains.kotlinx:kotlin-deeplearning-visualization:0.3.0")
Met de API van KotlinDL kun je alle stappen van het trainen van een model doorlopen: het inladen van de dataset, preprocessing van de data en het maken van een model. De API van KotlinDL is geïnspireerd door Keras, met een aantal wijzigingen waardoor je je code meer in de stijl van Kotlin schrijft.
Een dataset die je zeer eenvoudig in kunt laden is MNIST. Dit is een dataset met handgeschreven getallen. Een voorbeeld hiervan zie je in onderstaande afbeelding.
.jpg?width=76&name=mnist_3%20(1).jpg)
De dataset kan als volgt worden ingeladen. Hiermee zet je automatisch de trainingdata en testdata in aparte variabelen door middel van destructuring. De tweede regel laat zien dat er een ingebouwde methode is voor het opsplitsen van de data op basis van een ratio. Bij het opsplitsen komt het gedeelte van het getal wat je meegeeft als eerste component terug en de rest als tweede.
val (trainVal, test) = mnist()
val (train, validation) = trainVal.split(1.0 - validationSplit)
Naast je dataset heb je een model nodig om te trainen. Deze maak je door een volgorde van layers aan te geven. Aan iedere layer kun je (hyper)parameters meegeven, zoals welke activatiefunctie gebruikt wordt. In onderstaand voorbeeld zie je hoe je een convolutional classification-model opstelt met een aantal verschillende soorten layers.
private fun createModel() = Sequential.of(
Input(dims = longArrayOf(E1Constants.IMAGE_SIZE, E1Constants.IMAGE_SIZE, 1)),
Conv2D(filters = 6, kernelSize = longArrayOf(5, 5), activation = Activations.Relu),
AvgPool2D(poolSize = intArrayOf(1, 4, 4, 1)),
Flatten(),
Dense(outputSize = 20, activation = Activations.Relu),
Dense(outputSize = E1Constants.NUMBER_OF_CLASSES, activation = Activations.Softmax)
)
Een flexibelere manier om je model op te stellen is door een lijst van layers te gebruiken. In onderstaand voorbeeld wordt gebruikgemaakt van de buildList-functie, beschikbaar sinds Kotlin 1.6. Op deze manier kun je, met een voor Kotlin herkenbare manier van werken, zelf bepalen op welke manier je je model samenstelt.
private fun createModel(): GraphTrainableModel {
val layers = buildList {
add(Input(dims = longArrayOf(E1Constants.IMAGE_SIZE, E1Constants.IMAGE_SIZE, 1)))
repeat(2) {
val numberOfFilters = E1Constants.BASE_CONV_FILTERS * 2.0.pow(it).toLong()
add(
Conv2D(
filters = numberOfFilters,
kernelSize = longArrayOf(3, 3),
activation = Activations.Relu,
padding = ConvPadding.SAME,
kernelRegularizer = L2()
)
)
add(AvgPool2D(poolSize = intArrayOf(1, 2, 2, 1)))
add(Dropout(keepProbability = 0.7f))
}
add(Flatten())
add(Dense(outputSize = E1Constants.NUMBER_OF_CLASSES, activation = Activations.Softmax))
}
return Sequential.of(layers)
}
Vervolgens train en compileer je dit model. Bij het compileren van het model wordt aangegeven dat de accuracy metric van het model gemeten moet worden, zodat we die tijdens en na het trainen op kunnen vragen.
model.use {
this.compile(
optimizer = Adam(),
loss = Losses.SOFT_MAX_CROSS_ENTROPY_WITH_LOGITS,
metric = Metrics.ACCURACY
)
this.fit(
trainingDataset = train,
validationDataset = validation,
epochs = E1Constants.EPOCHS,
trainBatchSize = E1Constants.BATCH_SIZE,
validationBatchSize = E1Constants.BATCH_SIZE
)
}
Hieronder zie je hoe het model leert tijdens het trainen. De nauwkeurigheid van het model is in de logging zichtbaar als metric, omdat we dat bij het compileren als argument voor de metric hebben meegegeven. In onderstaande logging is te zien hoe het model binnen enkele epochs leert om handgeschreven getallen met een goede zekerheid te herkennen.

Verdere monitoring van de training is helaas niet beschikbaar, zoals je bijvoorbeeld met TensorBoard zou kunnen doen als je TensorFlow gebruikt. Wel is het mogelijk om zelf een callback te schrijven, die bijvoorbeeld aan het einde van iedere epoch aangeroepen wordt. In onderstaand voorbeeld zie je dat je in de callback toegang hebt tot een aantal gegevens uit de training, maar niet alles. Zo is de learning rate niet in te zien of aan te passen. Als je visualisaties wil van hoe je model presteert, dan zou je in deze callback zelf data voor visualisatie weg moeten schrijven. Vervolgens kun je deze data met andere software inzien, bijvoorbeeld op een dashboard.
class LoggingCallback : Callback() {
override fun onEpochEnd(epoch: Int, event: EpochTrainingEvent, logs: TrainingHistory) {
super.onEpochEnd(epoch, event, logs)
println("Epoch $epoch, loss: ${event.lossValue}, acc: ${event.metricValue}, val_loss: ${event.valLossValue}, val_acc: ${event.valMetricValue}")
}
}De MNIST-dataset wordt in het juiste formaat aangeboden door KotlinDL. Bij het trainen met een eigen dataset moet je vaak zelf nog preprocessing van de dataset doen. Hiervoor is een preprocess-functie beschikbaar, waarin je aangeeft welke transformaties op de inputdata uitgevoerd moeten worden.
preprocess {
load {
pathToData = File(datasetPath)
imageShape = ImageShape(channels = 3L)
colorMode = ColorOrder.BGR
labelGenerator = FromFolders(mapping = mapOf("cat" to 0, "dog" to 1))
}
transformImage {
resize {
outputHeight = E2Constants.IMAGE_SIZE.toInt()
outputWidth = E2Constants.IMAGE_SIZE.toInt()
interpolation = InterpolationType.BILINEAR
}
rotate {
degrees = 90f
}
}
}
Met bovenstaande pipeline kun je een aantal transformaties toepassen, die vooral gericht zijn op het correct inladen van de data. Augmentaties van data worden niet ondersteund, bijvoorbeeld de trainingdata willekeurig tussen de 30 en 70 graden draaien. Je kunt wel operaties toevoegen door zelf logica te schrijven, waarin je een BufferedImage aanpast. Het nadeel hiervan is dat die operaties automatisch op alle inputdata worden toegepast. Om augmentaties uit te voeren op je dataset zul je dus meerdere preprocessing pipelines moeten maken voor je training- en validatiedata, waardoor je meerdere keren je dataset inlaadt en voorbewerkt. Dit heeft een negatieve impact op performance en geheugengebruik. Het maken van al deze eigen augmentaties levert veel extra code op, wat tijd kost en extra onderhoud met zich meebrengt.
Bestaande modellen die je kunt inladen voor gebruik met KotlinDL zijn beschikbaar via twee model hubs: TFModelHub en ONNXModelHub. Beide hubs bevatten modellen die via Jetbrains aangeboden worden.
De TFModelHub bevat Keras-modellen en bijbehorende weights. Deze modellen worden direct ingeladen via de API van KotlinDL, waardoor ze volledig aan te passen zijn. Dit zorgt ervoor dat je transfer learning goed uit kunt voeren met deze modellen, door de laatste layers van het model te verwijderen en eigen layers toe te voegen die aansluiten bij de taak die je uit wil voeren. De al getrainde layers kun je finetunen of helemaal bevriezen, zodat je snel het nieuwe deel van het netwerk kunt trainen.
Modellen uit de ONNXModelHub kunnen niet direct gebruikt worden voor transfer learning. Omdat deze modellen worden ingeladen via de ONNX API voor Java, is een beperkte set aan functionaliteiten beschikbaar. Transfer learning kun je wel doen door zelf een ONNX-model te exporteren zonder de laatste layers, waarna je het model in KotlinDL als input voor een klein model kunt gebruiken. Dit zorgt ervoor dat je extra stappen moet zetten voordat je een ONNX-model kunt gebruiken.
Het inladen van modellen kan ook buiten de model hubs om. Deze modellen moeten in het H5-formaat zijn of in het SavedModelBundle-formaat van TensorFlow. In de documentatie van KotlinDL wordt uitgelegd hoe je een model in H5-formaat opslaat, terwijl je over het modernere SavedModelBundle-formaat kunt lezen in de documentatie van TensorFlow.
Een model gemaakt met de Sequential API van Keras bestaat uit layers die elkaar direct opvolgen en alleen verbindingen hebben met de volgende layer in het netwerk.
.png?width=282&name=Tekengebied%202%20(2).png)
Het inladen van een zelfgemaakt Sequential-model in H5-formaat werkt zonder problemen. In een minimaal aantal regels code kun je het opgeslagen model inladen, de weights terugzetten en het model gebruiken.
object E6Constants {
const val MODEL_CONFIG_PATH = "./models/custom_model_h5_simple/mnist.json"
const val MODEL_WEIGHTS_PATH = "./models/custom_model_h5_simple/mnist.h5"
}
fun main() {
Sequential.loadModelConfiguration(File(E6Constants.MODEL_CONFIG_PATH)).use {
it.compile(Adam(), Losses.SOFT_MAX_CROSS_ENTROPY_WITH_LOGITS, Metrics.ACCURACY)
it.loadWeights(HdfFile(File(E6Constants.MODEL_WEIGHTS_PATH)))
}
}
Vervolgens kun je het model gebruiken door een FloatArray met inputdata aan het model te geven. Belangrijk om te vermelden is dat ImageConverter ook een functie toNormalizedFloatArray heeft wat hetzelfde doet als de eerste twee regels van onderstaand codeblok. Helaas is die functie alleen nog maar geïmplementeerd voor afbeeldingen met drie kanalen in BGR-volgorde.
val image = ImageConverter.toBufferedImage(Sequential::class.java.classLoader.getResourceAsStream(E6Constants.IMAGE_RESOURCE_PATH)!!)
val imageArray = OnHeapDataset.toNormalizedVector((image.raster.dataBuffer as DataBufferByte).data)
val prediction = model.predict(imageArray)
Het resultaat is de index van de hoogst scorende outputnode. Het is ook mogelijk om alle outputs op te vragen met hun scores.
Een Functional-model is dynamischer dan een Sequential-model, omdat je de mogelijkheid hebt om een graaf van verbindingen te maken. Dit is in tegenstelling met de vaste volgorde van layers in een Sequential-model. Het inladen van een model werkt op een soortgelijke manier als bij een Sequential-model, maar dan door de functie loadModelConfiguration te gebruiken van de klasse Functional.
.png?width=690&name=Tekengebied%201%20(3).png)
Om het inladen van een complex model te testen, is een model getraind op basis van het DenseNet121-model dat Keras aanbiedt. Het inladen van dit model geeft twee problemen, waardoor het model niet via KotlinDL gebruikt kan worden.
Het eerste probleem is de naamgeving van de layers van het model. Blijkbaar worden deze in de Java-API van TensorFlow (wat KotlinDL op de achtergrond gebruikt) gevalideerd op basis van een bepaalde reguliere expressie. Hierdoor kan het model niet ingeladen worden, tenzij je de namen van de layers verandert met Python.
Als de namen eenmaal gewijzigd zijn, is het nog steeds niet mogelijk om het model in te laden. Er blijken layers te zijn die geen inbound nodes hebben, terwijl dat in Python geen probleem vormt. Het lijkt dus dat de Java-API van TensorFlow veel stricter is als het gaat om de validiteit van je model.
Tot slot is een object detection-model getraind met TensorFlow Object Detection API. Hierin staan layers die niet van Keras zijn en zijn er meerdere outputs. Het model is opgeslagen als een SavedModelBundle, wat het aangeraden formaat is van TensorFlow-modellen.
Het inlezen van deze SavedModelBundle levert uitdagingen op. Ten eerste geeft de predict-functie de waarde van maar één output-tensor terug. In het geval van een object detection-model is dit niet wenselijk: je wil de locaties van de boxes, de classes die erbij horen en de score. Zelfs bij het uitlezen van één tensor komt een foutmelding naar voren: Expects arg[0] to be uint8 but float is provided. Het is onduidelijk waar deze error precies vandaan komt, door de native code die TensorFlow gebruikt.
Omdat je zelf geen controle hebt over de TensorFlow-code die KotlinDL gebruikt, kun je dit niet oplossen. De API voor inference lijkt hiermee alleen ondersteuning te bieden voor specifieke datatypes voor de in- en outputs. Deze opzet werkt goed voor image classification, als je model ook de juiste datatypes gebruikt. Voor object detection zul je moeten wachten tot de ondersteuning daarvoor uitgebreid is. Wel biedt KotlinDL zelf pretrained object detection modellen aan, waar we nu naar gaan kijken.
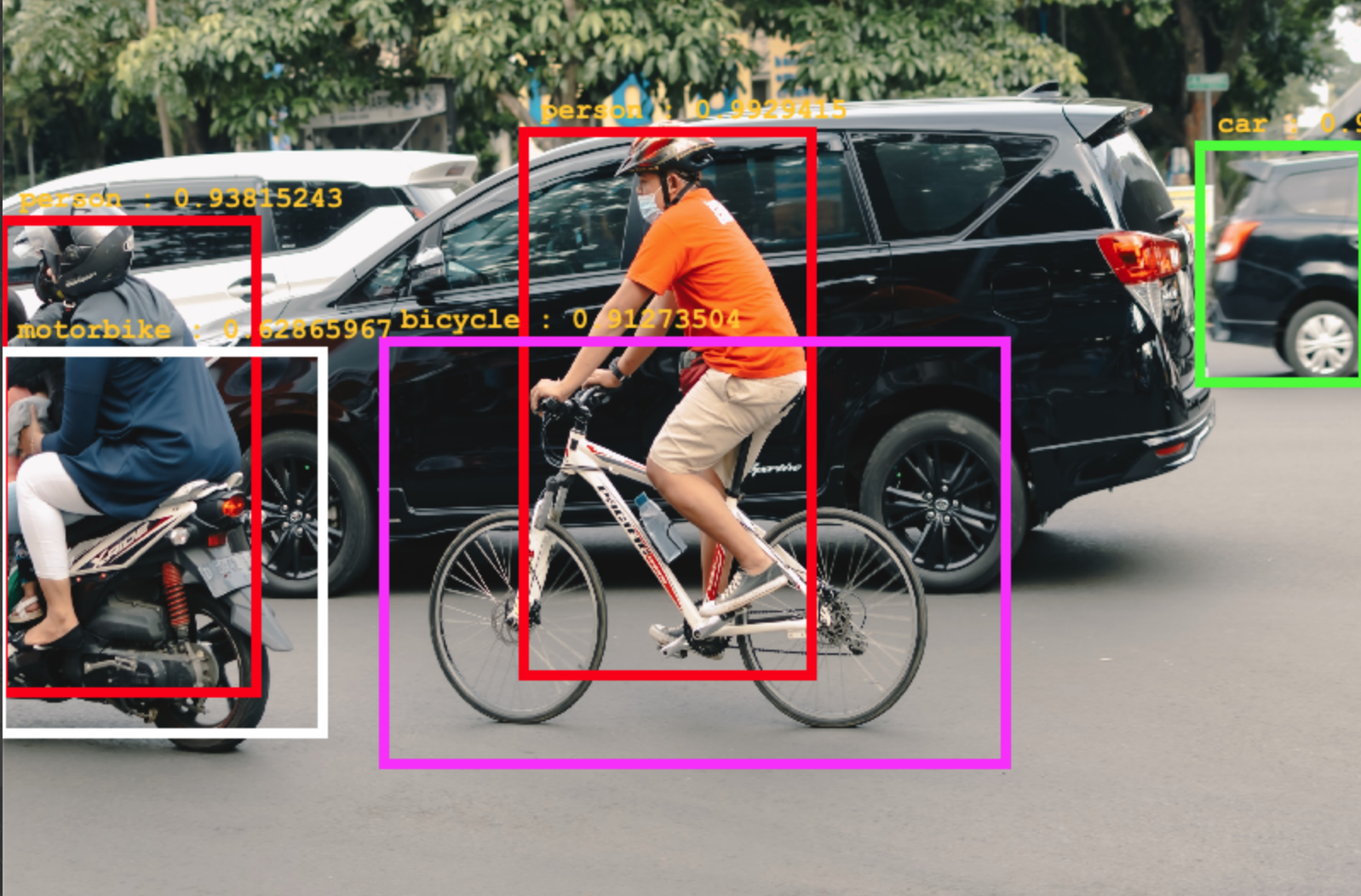
In tegenstelling tot Keras heeft KotlinDL out-of-the-box mogelijkheden voor het gebruik van pretrained object detection-modellen. Deze modellen zijn op dit moment alleen beschikbaar via de model hubs en zijn gelimiteerd in het aantal modellen dat ondersteund wordt. Op de roadmap staan meerdere modellen die nog toegevoegd gaan worden, zodat je meer keuze hebt. Wanneer er ondersteuning komt voor transfer learning of custom modellen is niet duidelijk.
Een voorbeeld van een model uit de ONNXModelHub is een SSD object detection-model. Dit model is het enige volledig uitgewerkte object detection-model dat je zonder configuratie kunt gebruiken op COCO-dataset classes. Let op: omdat dit model uit de ONNX model hub komt, kun je dit model niet zomaar fine-tunen op je eigen use case.
Object detection werkt hetzelfde als de andere modellen uit de model hubs. Het enige verschil is dat je het model aanroept met detectObjects in plaats van de predict-functie.
val modelType = ONNXModels.ObjectDetection.SSD
val modelHub = ONNXModelHub(cacheDirectory = File("cache/pretrainedModels"))
val model = modelHub.loadPretrainedModel(modelType)
model.use {
val imageFile = File(E3Constants.IMAGE_PATH)
val detectedObjects = this.detectObjects(imageFile = imageFile, topK = E3Constants.TOP_K)
detectedObjects.forEach {
println("${it.classLabel} found at ${it.xMin} ${it.yMin} ${it.xMax} ${it.yMax} with probability ${it.probability}")
}
}
De parameter topK van de detectObjects-functie geeft aan hoeveel resultaten je wil terugkrijgen, met de meest waarschijnlijke objecten als eerste.
Er zijn veel verschillen tussen KotlinDL en Keras. Veel van deze verschillen zijn klein en hebben vooral impact op hoe je je code moet schrijven, bijvoorbeeld de methodes van de API die je gebruikt. Ook is er een verschil in performance, al verschilt dit per model en configuratie van je systeem. In KotlinDL treedt er een vertraging in snelheid op na een aantal epochs, wat met Keras niet gebeurt. Er zijn echter ook een aantal grotere categorieën van verschillen te identificeren.
De eerste grotere categorie van verschillen is welke features er beschikbaar zijn. Keras is één van de meestgebruikte libraries voor deep learning. In het bijzonder is deze library geschikt voor beginners, vanwege de high-level API. De eerste versie van Keras is al meer dan zeven jaar oud en ondertussen heeft de library veel gebruikers. Een teken van deze populariteit is het aantal stars op GitHub, wat ten tijde van schrijven op 54k staat. In vergelijking daarmee is de eerste versie van KotlinDL bijna anderhalf jaar oud en zijn er bijna 800 stars op GitHub. Door zijn populariteit is Keras uitgegroeid tot een project met heel veel features en is Keras tegenwoordig zelfs onderdeel van TensorFlow.
Omdat KotlinDL erg nieuw is, zijn er missende features. Er wordt actief ontwikkeld om features die in Keras beschikbaar zijn ook beschikbaar te maken in KotlinDL. Een voorbeeld hiervan zijn de layers voor het opbouwen van je model. In de huidige versie, versie 0.3.0, missen layers die Keras wel aanbiedt. Op de roadmap voor versie 0.4.0 staat dat alle layers van Keras ook ondersteund worden in KotlinDL. Daarnaast worden veel meer modellen in de model hubs beloofd, zowel voor image classification als object detection.
KotlinDL biedt ook features die niet in Keras bestaan. Zo heeft Keras geen ingebouwde mogelijkheden voor object detection, zoals hiervoor beschreven staat. De ondersteuning hiervan is slechts een basis en KotlinDL geeft aan in toekomstige versies de ondersteuning van deze modellen uit te breiden.
Het ecosysteem van AI-gerelateerde libraries in JVM-talen is erg klein. Dit zorgt ervoor dat er weinig libraries zijn die je helpen om je model beter te trainen of gebruiken. Eerder werd al het voorbeeld van TensorBoard genoemd, maar dit geldt voor vrijwel alle externe libraries die je gebruikt in combinatie met Keras. In de vorige blog vertelden we je over Optuna, een framework voor het optimaliseren van hyperparameters. Ik heb geen soortgelijk framework kunnen vinden die met KotlinDL werkt.
Het grootste nadeel van een klein ecosysteem is dat je veel werk moet verzetten om iets te doen wat niet in KotlinDL zelf is geïmplementeerd. Naast dat dit veel werk oplevert, kan het veel complexiteit met zich meebrengen en loop je eerder tegen bugs of ongeoptimaliseerde oplossingen aan. Het zelf schrijven van deze libraries levert ook onderhoud op, totdat de open-source community rondom KotlinDL groot genoeg is om deze projecten te onderhouden.
De uitdagingen rondom het inladen van modellen (die niet met KotlinDL gemaakt zijn) zorgen ervoor dat KotlinDL niet aan te raden is als je met modellen uit andere frameworks aan de slag wil gaan, buiten de model hubs van KotlinDL om. Het is namelijk frustrerend als je op zoek moet gaan naar waarom iets niet werkt en je daar niets over kunt vinden op internet. Zeker als je nog weinig met deep learning hebt gedaan kun je hierin vastlopen.
De missende features en het kleine ecosysteem van KotlinDL zorgen ervoor dat het niet aan te raden is om KotlinDL op dit moment binnen een groot project te gebruiken. Wel kun je KotlinDL gebruiken om zelf aan de slag te gaan met het maken en het optimaliseren van modellen om daarvan te leren. De hoeveelheid nieuwe features die in de eerste paar releases zijn toegevoegd zorgt ervoor dat ik vertrouwen heb in de toekomst van KotlinDL. Hoe meer je ermee kunt, hoe makkelijker het wordt om KotlinDL aan te raden.
| Kotlin
Door Marcel van Heerdt / okt 2024