Problemen bij het trainen van face recognition-models. Zo los je ze op
Door Kevin Schomper / nov 2021 / 1 Min

Door Albert Veldman / / 7 min

Binnen het Avisi Labs-team werken we geregeld met Deep Learning. Recentelijk hebben wij voor een klant een opdracht uitgevoerd, waarin we meerdere ongerelateerde waardes voorspellen. De input waarmee wij dit moesten doen was niet voor alle waardes hetzelfde. Daarom hebben wij voor elke waarde een compleet nieuw netwerk getraind en geoptimaliseerd. Voor al deze netwerken hebben we opnieuw bepaald wat hier een goede structuur voor was. Dit was een tijdsintensief proces.
De structuur van een neuraal netwerk heeft, onder andere, invloed op het leervermogen en de trainingssnelheid van het netwerk. Het verschil tussen een degelijke en een goede structuur kan groot zijn. In ons geval kan het verschil oplopen tot 10% vaker de juiste voorspelling. Voor het vinden van een goede structuur voor je neurale netwerk zijn vele technieken beschikbaar. Toch komt het, net als bij het trainen van het netwerk, grotendeels neer op het volgende:

Bron: xkcd 1838
Tijdens het uitvoeren van de opdracht voor de klant vonden wij Optuna. Optuna is een ''Hyperparameter Optimization Framework''. Hiermee optimaliseer je de hyperparameters van verschillende Machine Learning-modellen voor een efficiëntere en betere resultaten. Dit heeft ons geholpen bij het maken van verschillende netwerken. In deze blog vertel ik je wat Optuna te bieden heeft, hoe wij dit toegepast hebben én hoe je er zelf mee aan de slag kunt gaan. Enige voorkennis van deep learning en convolutional neural networks is vereist. Heb je deze kennis niet? Dan raad ik je aan om deze korte introductie door te lezen. De voorbeelden in deze blog zijn te vinden in onze GitHub repository. Hier vind je twee Jupyter Notebook-bestanden, waarmee je de voorbeelden die in deze blog staan zelf kunt uitvoeren. In de README staan verdere instructies voor het starten van Jupyter Lab en het installeren van de vereiste dependencies.
Om duidelijk te maken wat hyperparameters zijn, beginnen we bij parameters. In afbeelding één wordt een simpel neuraal netwerk weergegeven.
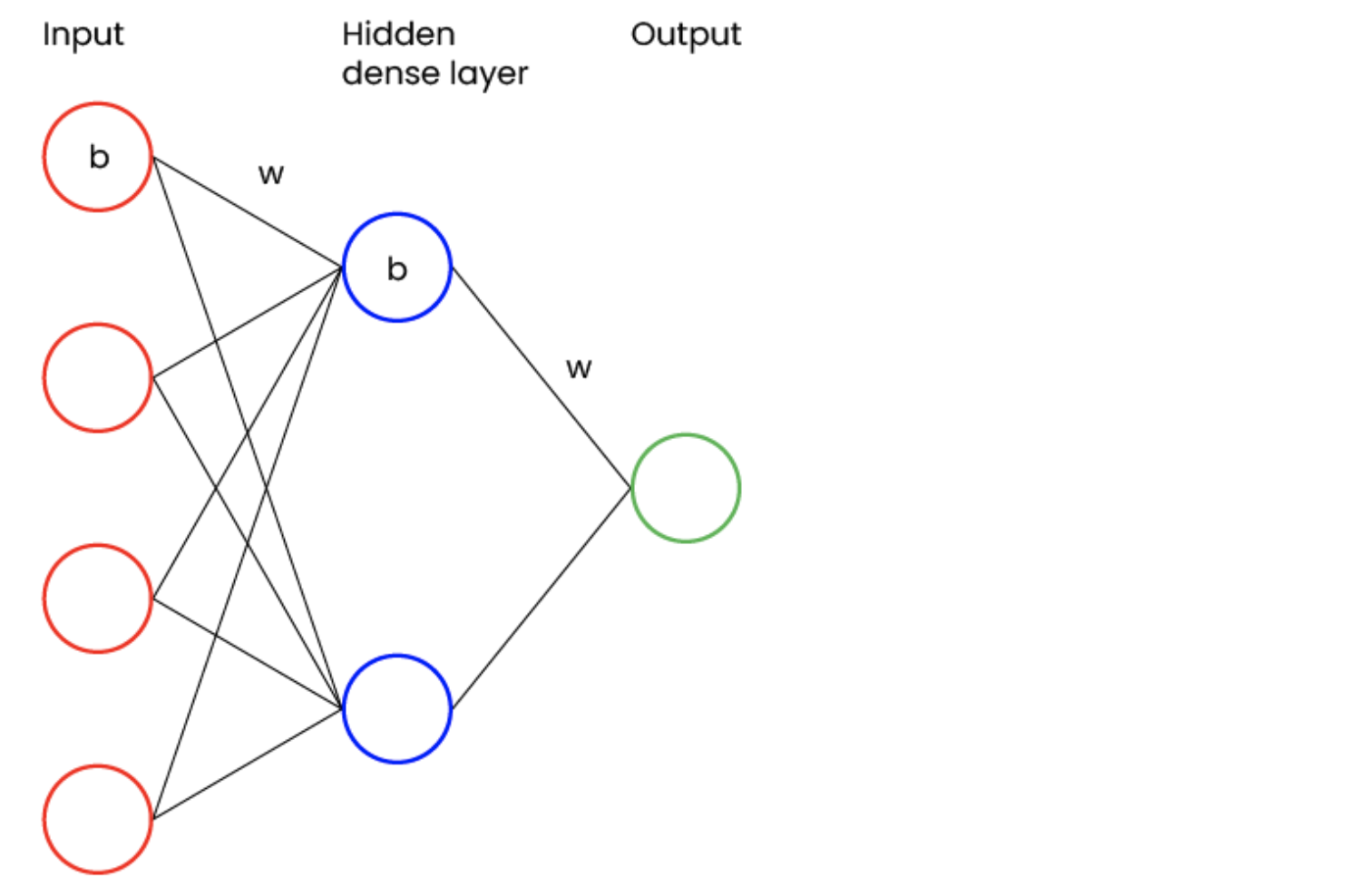
Afbeelding 1: Neuraal Netwerk
Elke node bevat een bias (b). Elke verbinding tussen nodes bevat een weight (w). Weights en biases zijn klassieke voorbeelden van parameters van het neurale netwerk. Dit wordt tijdens het trainen van het netwerk geoptimaliseerd en is niet gebruikelijk om zelf in te stellen. Wil je meer weten over de invloed van weights en biases in neurale netwerken? Klik dan hier.
Wat je wél zelf instelt, bij het trainen van een netwerk, zijn de hyperparameters. Dit kunnen hidden layers zijn, het aantal nodes in deze layers en de activation functions van de nodes.
Zoals eerder is benoemd, is Optuna een Hyperparameter Optimization Framework waarmee je hyperparameters van Machine Learning-modellen optimaliseert. Deze hyperparameters kunnen een grote invloed hebben op de nauwkeurigheid van het netwerk én de trainingstijd voordat deze nauwkeurigheid bereikt wordt. Stel dat je een convolutional neural network traint voor het classificeren van objecten in foto's, dan kan een netwerk er zoals in afbeelding 2 uit komen te zien.
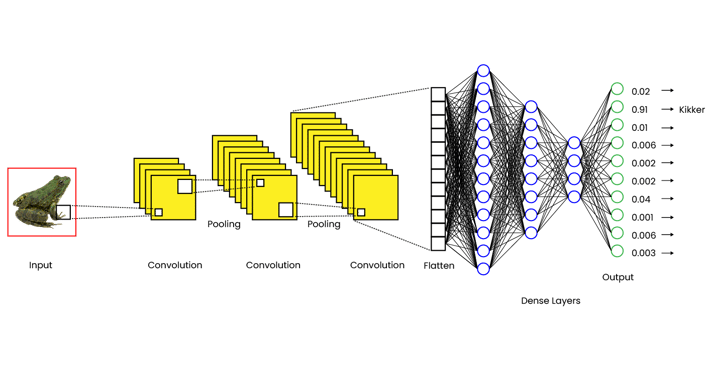
Afbeelding 2: Convolutional Neural Network
Voor bovenstaande netwerk kun je meer hyperparameters instellen dan voor ons eerdere neurale netwerk. Zo kun je het aantal convolutional layers aan de linkerkant of het aantal dense layers aan de rechterkant aanpassen. De hoeveelheid opties en de invloeden hiervan maken het complex om zelf een goede combinatie te vinden van hyperparameters.
De manier waarop Optuna hyperparameters optimaliseert is vergelijkbaar met de manier waarop parameters in het netwerk geoptimaliseerd worden. Bij het trainen van een neuraal netwerk worden, aan het begin, waardes bepaald voor de parameters. Deze worden, na elke epoch in het trainingsproces, in de goede richting gestuurd op basis van de nauwkeurigheid van het netwerk. Optuna doet dit een niveau hoger. Optuna stuurt de hyperparameters bij op basis van de nauwkeurigheid van het netwerk, aan het einde van het trainingsproces. Hierna traint het een nieuw netwerk. Zoals in afbeelding 3 is weergegeven, resulteert dit in meerdere netwerken met een zo hoog mogelijke nauwkeurigheid.
Voor ons voorbeeld betekent dit, dat het bovenstaande netwerk slechts één van de structuren is die Optuna uitprobeert.
.png?width=1707&name=3%20(1).png)
Afbeelding 3: Optuna trials van Convolutional Neural Network
De verschillende combinaties van hyperparameters geven uiteenlopende resultaten. Door op een gestructureerde manier waardes te kiezen voor de hyperparameters, bepaalt Optuna welke hyperparameters de grootste invloed hebben op het resultaat én of het aanpassen van hyperparameters effect heeft.
Voor het bepalen van weights en biases in een netwerk worden algoritmes gebruikt, zoals backpropagation. Optuna gebruikt verschillende algoritmes om de volgende waardes voor de hyperparameters te bepalen. Dit zijn sampling algoritmes. Op dit moment zijn er vier sampling algoritmes om uit te kiezen. De standaard is de Tree-structured Parzen Estimator (TPESampler). Deze wordt gebruikt in de voorbeelden in deze blog.
Het trainen van neurale netwerken kan, afhankelijk van de complexiteit, veel tijd in beslag nemen. Optuna traint meerdere netwerken, waardoor het lang kan duren voordat je een goede combinatie van hyperparameters vindt. Zo kan het vijftien minuten duren om één simpel netwerk te trainen. Als je Optuna de hyperparameters laat optimaliseren, in zestig iteraties, dan kan dit tot vijftien uur duren!
Om deze tijd te beperken, wordt gebruikgemaakt van een pruning algoritme, zoals de Hyperband Pruner. Dit algoritme bepaalt of de tussentijdse resultaten goed genoeg zijn om het trainen voort te zetten.
Optuna kan de hyperparameters niet aanpassen tijdens het trainen, maar wel de prestaties van het netwerk tijdens het trainen bekijken en vroegtijdig beëindigen. De prestaties van de huidige hyperparameters worden door het algoritme vergeleken met de resultaten van eerdere iteraties. Als de huidige combinatie slechter presteert, zal het trainen worden beëindigt. Naarmate er meer iteraties afgerond zijn, zal het pruning algoritme steeds vaker het trainen vroegtijdig beëindigen, omdat de kans dat een eerdere iteratie beter was steeds groter wordt.
Sampling- en pruning algoritmes hebben beide een bepaald aantal iteraties nodig om de beste prestaties te bereiken. Voor de combinatie van de TPE-sampler en de Hyperband pruner raden we aan om minimaal 40 iteraties, oftewel trials, te draaien om mee te beginnen. Hierna zijn de algoritmes "opgewarmd" en kun je betere resultaten verwachten.
Ter illustratie van de mogelijkheden van Optuna maken we een convolutional neural network dat de categorieën van de afbeeldingen in de CIFAR-10 dataset bepaalt. De benodigde dataset is via Keras te importeren en bevat afbeeldingen van 10 categorieën met 6.000 afbeeldingen per categorie. Dit zijn alledaagse categorieën, zoals kikkers en auto's. Onderstaande code is terug te vinden in het CIFAR-10 classic CNN.ipynb-bestand in de GitHub repository.
Ten eerste maken we een convolutional neural network met twee convolutional layers en één dense layer. De code is in codeblok 1 weergegeven.
model = keras.Sequential([
layers.Input((32,32,3)),
layers.Conv2D(32, (3,3), activation="relu", padding="same"),
layers.MaxPooling2D(),
layers.BatchNormalization(),
layers.Dropout(0.2),
layers.Conv2D(64, (3,3), activation="relu", padding="same"),
layers.Flatten(),
layers.Dense(32, activation="relu"),
layers.Dropout(0.2),
layers.Dense(10, activation="softmax")
])
model.compile(loss=keras.losses.CategoricalCrossentropy(),
optimizer=keras.optimizers.Adam(),
metrics=["accuracy"])
reduce_lr_callback = keras.callbacks.ReduceLROnPlateau(
monitor="val_loss", factor=0.75, patience=5, min_lr=0.00001
)
callbacks = [
reduce_lr_callback
]
history = []
history = model.fit(
train_images,
train_labels,
epochs = 50,
batch_size = 64,
validation_data = (val_images, val_labels),
callbacks = callbacks
)
Codeblok 1: Initieel model
Dit netwerk is waarschijnlijk niet complex genoeg om alle eigenschappen van de afbeelding vast te leggen. Als we het netwerk trainen, zien we dit terug in de resultaten. Zoals hieronder weergegeven haalt het model, op data die het nog niet eerder gezien heeft, een accuracy van slechts 45%.  Afbeelding 4: Accuracy eerste model
Afbeelding 4: Accuracy eerste model
We weten nu welk structuur dit probleem niet gaat oplossen, maar welk structuur kan dit probleem wel oplossen? Optuna helpt ons hierbij. Onderstaande code is terug te vinden in de GitHub repository in het CIFAR-10 Optuna.ipynb-bestand.
Het aanmaken van het model gebeurt hier anders, omdat we deze opbouwen op basis van de door Optuna gegeven waardes. Het optimaliseren van hyperparameters wordt door Optuna een study genoemd. Een study bestaat uit trials, waarin hyperparameters daadwerkelijk worden getest. Om in een trial een nieuw netwerk te maken, plaatsen we de code in een aparte fuctie. Zie codeblok 2.
def create_model(trial):
metrics = [
"accuracy"
]
dense_layers = trial.suggest_int("dense_layers", 1, 5)
conv_layers = trial.suggest_int("conv_layers", 1, 5)
dense_nodes = trial.suggest_categorical("dense_nodes", [512, 256, 128, 64])
conv_filters = trial.suggest_categorical("conv_filters", [64,32,16])
model = keras.Sequential()
model.add(layers.Input((32,32,3)))
model.add(layers.Conv2D(conv_filters, (3,3), activation="relu", padding="same"))
for i in range(1, conv_layers):
model.add(layers.MaxPooling2D())
model.add(layers.BatchNormalization())
model.add(layers.Dropout(0.2))
# Increase filter size as patterns get more complex further in the network
conv_filters *= 2
model.add(layers.Conv2D(conv_filters, (3,3), activation="relu", padding="same"))
model.add(layers.Flatten())
model.add(layers.Dense(dense_nodes, activation="relu"))
for i in range(1, dense_layers):
# The optimal size of the amount of nodes in a hidden layer is usually between the size of the previous and next layer
# so we devide the number of nodes by 2 each layer
dense_nodes /= 2
model.add(layers.Dense(dense_nodes, activation="relu"))
if i % 2 == 0:
model.add(layers.Dropout(0.2))
model.add(layers.Dense(10, activation = "softmax"))
loss = keras.losses.CategoricalCrossentropy()
model.compile(loss = loss, optimizer = keras.optimizers.Adam(), metrics = metrics)
return model
Codeblok 2: Model maken d.m.v. Optuna trial
Binnen create_model vragen we het trial object om vier waardes: het aantal dense layers, convolutional layers, dense nodes en convolutional filters. Om de duur van de study te beperken, hebben we de mogelijke waardes al vastgesteld. Nu maken we een model op basis van deze waardes. Optuna verwacht een objective functie waaraan de trial meegegeven kan worden en waar een waarde uitkomt. Deze waarde moet op een manier verbonden zijn aan de gekozen hyperparameters. In ons voorbeeld is het gekoppeld doordat de structuur van het netwerk invloed heeft op de loss die we teruggeven. Binnen onze objective functie, die hieronder is weergegeven in codeblok 3, maken we gebruik van create_model uit het codeblok 2 om dit model te trainen.
def objective(trial):
keras.backend.clear_session()
model = create_model(trial)
reduce_lr_callback = keras.callbacks.ReduceLROnPlateau(
monitor="val_loss", factor=0.75, patience=5, min_lr=0.00001
)
callbacks = [
TFKerasPruningCallback(trial, "val_loss"),
reduce_lr_callback,
tf.keras.callbacks.EarlyStopping(patience=5)
]
history = model.fit(
train_images,
train_labels,
epochs=30,
batch_size=32,
validation_data=(val_images, val_labels),
callbacks=callbacks
)
return history.history["val_loss"][-1]
Codeblok 3: Objective functie
Aan het trainen van het model voegen we callbacks toe voor het vroegtijdig stoppen van het trainen en het verlagen van de learning rate als de loss niet meer afneemt. Wanneer het trainen is afgerond, returnen we de loss op de validatie-set, zodat Optuna kan bepalen hoe goed de gekozen hyperparameters waren in vergelijking met die van eerdere trials.
Ten slotte starten we in codeblok 4 het optimaliseren. Dit doen we door een nieuwe study te maken, waaraan we de gewenste pruner en sampler meegeven. We geven aan dat de waarde die we uit de objective functie krijgen zo laag mogelijk moet zijn.
study = optuna.create_study(
direction = "minimize",
study_name="atl-optuna-9",
storage="sqlite:///example.db",
pruner=optuna.pruners.HyperbandPruner(),
sampler=optuna.samplers.TPESampler(multivariate=True),
load_if_exists=True
)
study.optimize(objective, n_trials=80)
Codeblok 4: Study starten
Door de study een naam en storage mee te geven, kunnen we de resultaten terugzien in het Optuna Dashboard. Hier zie je resultaten van de verschillende modellen en kun je conclusies trekken over de hyperparameters. Zo concluderen we uit het onderstaande overzicht dat het resultaat bijna volledig afhankelijk is van het aantal convolutional layers.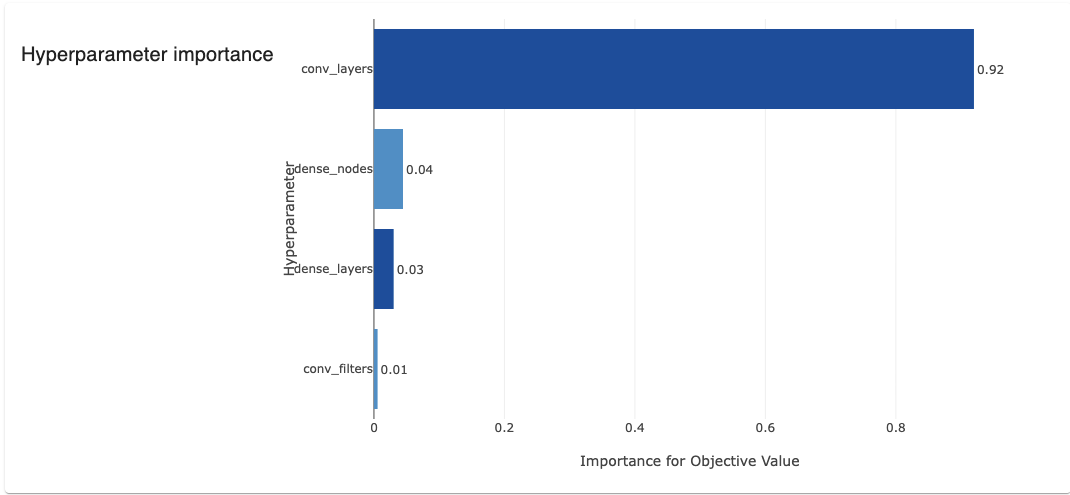 Afbeelding 5: Hyperparameter importance in Optuna Dashboard
Afbeelding 5: Hyperparameter importance in Optuna Dashboard
Na het afronden van de study vragen we de statistieken en de beste hyperparameters van het object op: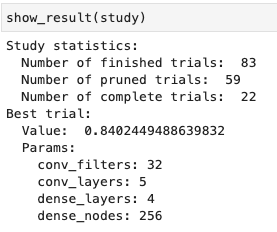
Afbeelding 6: Resultaten Optuna study
De beste resultaten zijn in de trials behaald, waarin een groter aantal convolutional layers is gebruikt. Het maximum wat we hebben toegestaan is vijf. Mogelijk halen we betere resultaten door dit maximum te verhogen. Echter, dit resulteert tot een langere trainingstijd. In een écht project wil je dit zeker onderzoeken, maar voor nu houden we het bij de huidige vijf layers.
Nu we een betere structuur gevonden hebben, trainen we opnieuw een netwerk. Dit doen we voor een groter aantal epochs dan Optuna heeft gedaan. Dit model is, door de extra convolutional layers en dense layers, een stuk complexer dan het eerdere model:
optimized_model = keras.Sequential([
layers.Input((32,32,3)),
layers.Conv2D(32, (3,3), activation="relu", padding="same"),
layers.MaxPooling2D(),
layers.BatchNormalization(),
layers.Dropout(0.2),
layers.Conv2D(64, (3,3), activation="relu", padding="same"),
layers.MaxPooling2D(),
layers.BatchNormalization(),
layers.Dropout(0.2),
layers.Conv2D(128, (3,3), activation="relu", padding="same"),
layers.MaxPooling2D(),
layers.BatchNormalization(),
layers.Dropout(0.2),
layers.Conv2D(256, (3,3), activation="relu", padding="same"),
layers.MaxPooling2D(),
layers.BatchNormalization(),
layers.Dropout(0.2),
layers.Conv2D(1024, (3,3), activation="relu", padding="same"),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dropout(0.2),
layers.Dense(32, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dropout(0.2),
layers.Dense(8, activation="relu"),
layers.Dense(10, activation="softmax")
])
optimized_model.compile(loss=keras.losses.CategoricalCrossentropy(),
optimizer=keras.optimizers.Adam(),
metrics=["accuracy"])
Codeblok 5: Model met beter aantal convolutional layers
Na het trainen van het bovenstaande netwerk zien we hieronder een accuracy van bijna 80% op data die het model niet eerder gezien heeft. Ons eerste model had een accuracy van 45%. Een flinke verbetering dus!
.png?width=613&height=101&name=image2022-2-15_15-58-55%20(1).png)
Afbeelding 7: Accuracy met geoptimaliseerde convolutional layers
We kunnen de hyperparameters van dit netwerk nog beter maken. We weten nu dat, van onze gegeven opties, vijf convolution layers het beste resultaat geeft. Door de grote invloed van deze hyperparameters weten we niet of de andere hyperparameters beter werken. Door het aantal convolutional layers vast te zetten en een nieuwe study te maken, kunnen we de andere hyperparameters optimaliseren. Zo bereiken we mogelijk betere resultaten.
Na het uitvoeren van een paar studies, om de overgebleven hyperparameters te optimaliseren, hebben we het volgende resultaat:
Het resultaat van dit netwerk is in afbeelding 8 weergegeven. Het geeft, zoals verwacht, betere resultaten dan ons vorige netwerk. Na het trainen hebben we een accuracy van 82%, op data die het model niet eerder heeft gezien, ten opzichte van 80%.

Afbeelding 8: Accuracy van geoptimaliseerd netwerk
Als je een probleem wilt oplossen door middel van een neuraal netwerk, dan kom je er niet onderuit dat je meerdere netwerkstructuren moet proberen om de beste resultaten te behalen. Het proces bestaat voornamelijk uit proberen en onderbreken als het resultaat niet veelbelovend is. Optuna automatiseert dit proces, waardoor je jouw tijd aan andere zaken kunt besteden. In de bovenstaande voorbeelden hebben we Optuna beperkt in de zoekrichting. Heb je meer tijd of een krachtigere computer? Dan kun je deze beperkingen loslaten en zullen de algoritmes van Optuna écht tot hun recht komen.
Alle code voor het trainen van je eigen neurale netwerk en het optimaliseren hiervan met Optuna is beschikbaar in de GitHub repository.
| TechLab
Door Albert Veldman / okt 2024