Consistent performance testing with Oracle, is it possible?
Door Avisi / dec 2012 / 1 Min

Door Erik Evers / / 5 min

One of our customers has a problem: they have millions of unorganized documents that have not been digitized yet. This makes finding the right document very complicated. Here at Avisi Labs, we are working on a digital solution for this issue. Our solution makes it possible to search for documents (once they are digital) by adding metadata, such as document type (e.g. "manual" or "technical specification"). In this blog, I will describe how we performed OCR (Optical Character Recognition) to extract the contents of documents using the Google Vision API and how we trained a machine learning model that is able to determine document types.
The Google Cloud platform offers two computer vision products that use machine learning:
We're using the Vision API feature to extract the contents from each document by performing OCR. The documents are sent to and from the API through the Go client library. This enables us to speed things up by using Goroutines. This is very useful because of the rate limits that Google sets to the use of the Vision API. To put this into numbers, we can only perform OCR on 16 images or a total of 8 MB per request.
We start things off by converting our documents from PDF files to JPEG images. Though OCR can be performed on PDF documents, our research found that the Vision API was unable to recognize text within images in PDF documents. The same problem occurs when a page is entirely made up of one image, which is something that is the case in our dataset of scanned documents. Want to know if your document can be put through Vision API? Open your document with a program like Adobe Acrobat Reader. If you are able to select individual words and sentences on the page, then those parts of the PDF document can be recognized by the Vision API. If not, the Vision API will not recognize this text. This problem can be avoided by sending the documents as JPEG images instead of PDF documents.
We convert our PDF documents to JPEG images using the Imagick library. Each page in a document is converted to a separate image. The converted images are sent to the Vision API and we get a JSON response for each image which includes the text that was detected in the image. The contents of each page are merged together to get one file that contains the contents of our document.
Take for example the following PDF file, the directions to our offices in Arnhem:

The steps that we have to perform on this document are:
AVISI
Praktische Informatie
Nieuwe Stationsstraat 10, 6811 KS Arnhem
Routebeschrijving auto
Welke parkeergarage moet ik hebben, en hoe kom ik daar?
Wanneer u gebruik maakt van een navigatiesysteem, dan kunt u Willemstunnel 1 te Arnhem
aanhouden. U komt dan voor de ingang van Parkeergarage Centraal uit.
Er zijn meerdere uitgangen, maar deze gaan niet allemaal naar het WTC.
Gebruik trappenhuis 1 of trappenhuis 3 om op het kantorenplein uit te komen.
Neem vervolgens de lift naar +1 en u vindt ons in de blauwe WTC-toren.
Vanuit de richting Den Haag/Utrecht
• Volg de A12 richting Arnhem
• Neem afrit 25 Oosterbeek
Na 400 meter rechtsaf de Amsterdamseweg (N224) op richting Oosterbeek
Na 8,2 kilometer rechtsaf het Willemsplein op
Houd na 120 meter rechts aan
• In de tunnel vindt u de ingang van Parkeergarage Centraal.
Vanuit de richting Apeldoorn/Zwolle
Volg de A50 richting Arnhem
• Neem afrit 20 Arnhem Centrum en volg de Apeldoornseweg
• Na 5,1 kilometer links aanhouden op Apeldoornseweg
Na 0,5 kilometer bij stoplichten rechtsaf de Jans buitensingel op
| Linkerbaan aanhouden tot na le stoplichten, na 2e stoplichten in de tunnel rechts aanhouden
• Hier vindt u de ingang van Parkeergarage Centraal.
AVISI
Openbaar vervoer
Als ik op het station aankom, waar moet ik dan heen?
Loop de stationshal uit en neem roltrap naar boven. Wanneer je buiten komt zie je
de blauwe WTC-toren.
Kan ik vanuit de stationshal in het pand komen?
Je kunt niet direct vanuit de stationshal in het pand komen. Het is wel vlakbij!
Eerst even naar buiten lopen (aan de kant van het busstation) en dan naar
rechts, de blauwe WTC-toren met het AVISI logo!
Excelleren door software
Bel ons:
088 - 284 74 00
E-mail:
info@avisi.nl
After we perform OCR and extract the actual contents from all of the PDF documents, we proceed by training a Natural Language Processing model. This model will be able to predict a document type based on the contents of the document.
When training a machine learning model, we can't just pass the raw text data as input. We have to create a feature vector. Features are numerical values which represent some characteristic of the contents of a document. The feature vector is created by calculating the Term Frequency, Inverse Document Frequency (TFIDF) for each term in our contents. This measurement represents the importance of the terms in each document.
Our TFIDF Vectorizer considers both unigrams and bigrams. Unigrams are single terms and bigrams are pairs of terms. This distinction is made because a pair of terms may have a different meaning than a single term. For example, take the unigram market and compare it to the bigram stock market.
Calculating the statistics of the terms in our documents creates a TFIDF Vectorizer which contains a feature vector for each of our documents. In our project, the feature vector consists of 3596 different features per document. This feature vector enables us to train a machine learning model using supervised learning. But first, we must check if we can expect a good performing machine learning model.
We want to check if we can really classify different document types based on our feature vector. By plotting our feature vector for each document, we can see if there are some areas with clusters of one document type. The problem is that the feature vector consists of 3596 different features. This leads to a high-dimensional space. To be able to plot our vector, we use the dimensionality reduction technique t-SNE (t-distributed stochastic neighbor embedding). This keeps points that are nearby in the high-dimensional space close to each other in our projected space. As a result, we are able to plot our feature vectors in two dimensions, which can be seen in the figure below.
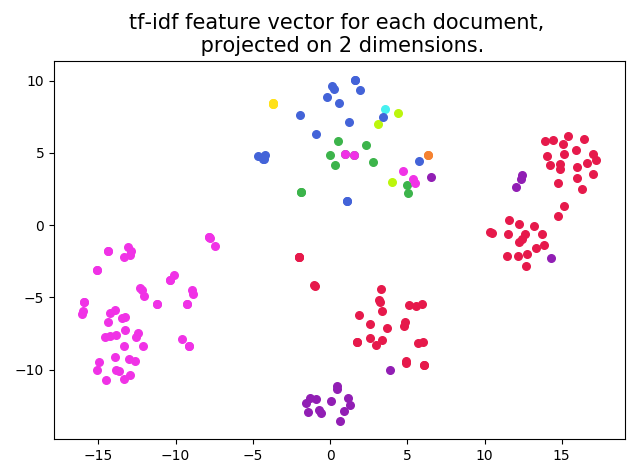
In this plot, the different colours correspond with the different document types. We clearly see some clusters of one document type, which indicates that it is possible to achieve a high accuracy classification when training a machine learning model with our feature vectors.
Based on the feature vectors we've created and a known document type for our documents in the dataset, we can train the machine learning model. This model will be able to predict the correct document type for new documents. We used some supervised learning models from Scikit-learn, a Python package that provides these models. How well a model performs depends on the data you use. It is recommended to evaluate the accuracy of different models and choose the one that achieves the highest accuracy.
Once our model has been trained, it is possible to predict a document type for any new documents. By following the same steps, we perform OCR and create a feature vector for these documents. The feature vector is passed to the trained model and our model will predict the correct document type for new documents.
There are multiple steps you have to take to train a machine learning model that is able to predict the correct document type of a document:
| Software Development
Door Erik Evers / okt 2024