Flexibele dataverwerking met een takenarchitectuur
Door Marcel van Heerdt / jan 2022 / 1 Min

Door Albert Veldman / / 12 min

In de huidige digitalisering komt het vaak voor dat je jaren aan documentatie digitaal inzichtelijk wil maken. Een van de grote voordelen hiervan is de mogelijkheid om snel in al deze documentatie te kunnen zoeken. Bijvoorbeeld het vinden van alle documenten die een exacte tekst bevatten of het vinden van de beste match bij je zoekopdracht. Bij het inrichten van een zoekmachine komt veel kijken, zoals het in kaart brengen van alle categorieën waarop gezocht wordt. Als dit er honderden zijn of vaak aangepast wordt, sta je voor een grote uitdaging. Hier hebben wij een oplossing voor.
In de opdracht die wij uitgevoerd hebben voor PWN, het waterleidingbedrijf van Noord-Holland, hebben wij een systeem gemaakt waarin miljoenen documenten en video's (vanaf nu informatieobjecten) geanalyseerd en vervolgens gezocht kunnen worden op basis van domeinspecifieke metadata, zoals het type leiding. Voor dit project zijn informatieobjecten aangeleverd die niet allemaal een vaste structuur of inhoud hebben. Uit deze objecten wordt door middel van AI allerlei metadata verkregen waar vervolgens op gezocht kan worden. Meer informatie over PWN en dit systeem staat op deze pagina.
Voor het zoeken door middel van domeinspecifieke data is een zoekmachine vereist en een van de mogelijke opties is Elasticsearch. Elasticsearch is een open source search engine waarmee je grote hoeveelheden data kunt doorzoeken en analyseren. Het is bovendien erg snel, schaalbaar door middel van een cluster en tot in de puntjes te configureren. Via de configuratie is het onder andere mogelijk om velden aan te maken die geïndexeerd moeten worden, zoals titels en auteurs, en vervolgens gebruikt kunnen worden in queries. In onze opdracht was er zo'n grote verscheidenheid aan velden nodig dat we er voor hebben gekozen om alle velden in Elasticsearch generiek te maken. Dit beperkt, naast de complexe configuratie, ook de tijd die besteed wordt aan het toevoegen van nieuwe velden aan deze configuratie.
De verschillende informatieobjecten koppelen we in de backend aan de generieke Elasticsearch velden door voor alle soorten informatieobjecten te definiëren welke informatie in welk Elasticsearch veld hoort. Om dit proces eenvoudiger te maken hebben we een annotatie gemaakt waarmee je dit kunt doen. Informatieobjecten waarin deze annotatie voorkomt worden uitgelezen en omgezet naar een zoekobject dat geïndexeerd kan worden in Elasticsearch.
De voorbeelden die in deze blog gebruikt worden zijn terug te vinden in de GitHub repository, de link vind je onderaan deze blog. Bekijk de video bovenaan deze pagina voor een demo van de applicatie.
In deze blog beschrijf ik de werking van Elasticsearch en onze custom annotations aan de hand van de webwinkel van een fictieve slijterij. Ik voeg een nieuw soort drank toe aan de applicatie door middel van onze annotations.
Om een biertje te kunnen vinden in onze bierwinkel moet deze eerst opgeslagen worden in MongoDB en vervolgens geïndexeerd worden in Elasticsearch. Het resultaat van een zoekopdracht in Elasticsearch is het MongoID van het originele object dat in MongoDB staat. Als de zoekopdracht een resultaat oplevert kunnen we met dit resultaat het originele object ophalen en terugsturen naar de gebruiker. Dit proces is in de onderstaande afbeelding gevisualiseerd.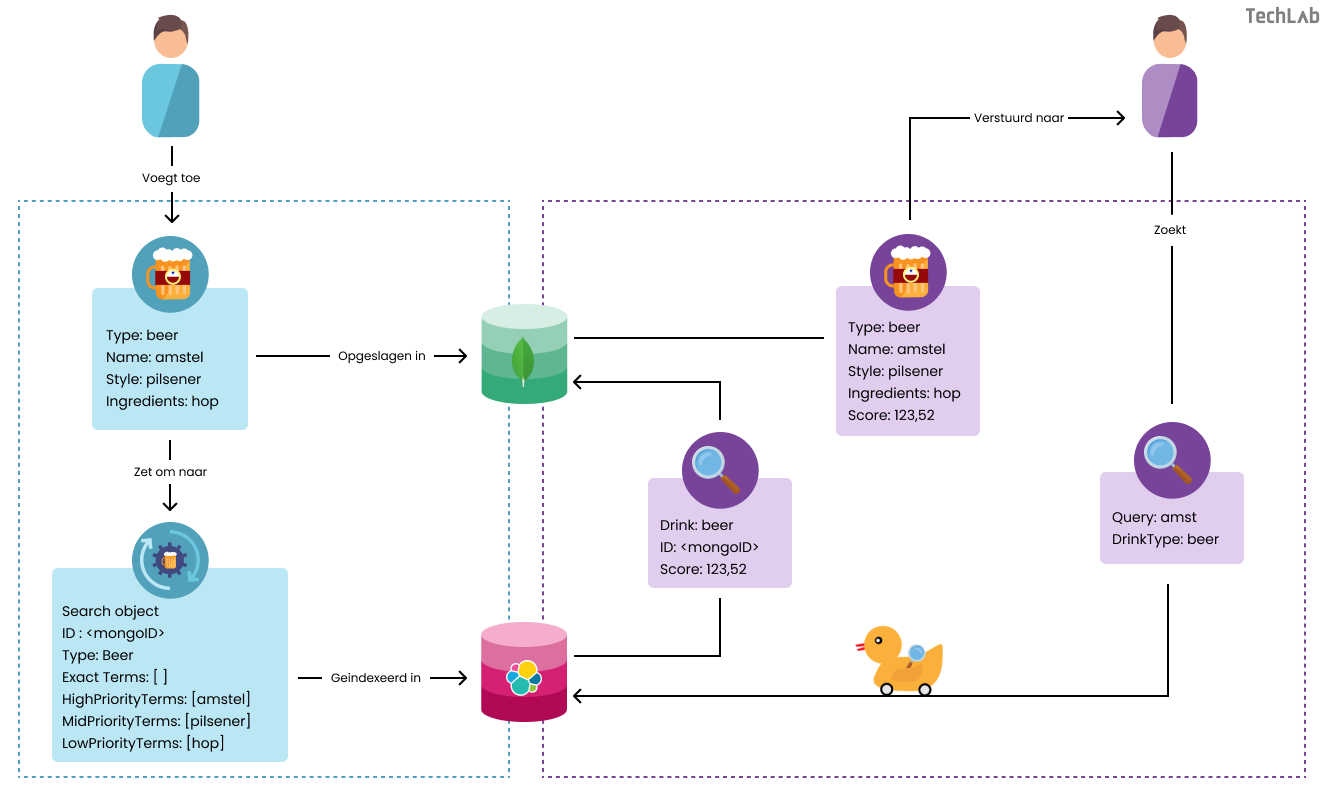
De applicatie voor deze casus is geschreven in Kotlin en maakt gebruik van Spring Boot. De structuur van de applicatie is in de onderstaande afbeelding weergegeven. De gebruiker kan door middel van een HTTP-verzoek de verschillende controllers benaderen. De controllers sturen dit verzoek door naar de services die het verzoek herstructureert voor de repositories. Tenslotte communiceren de repositories met MongoDB en Elasticsearch.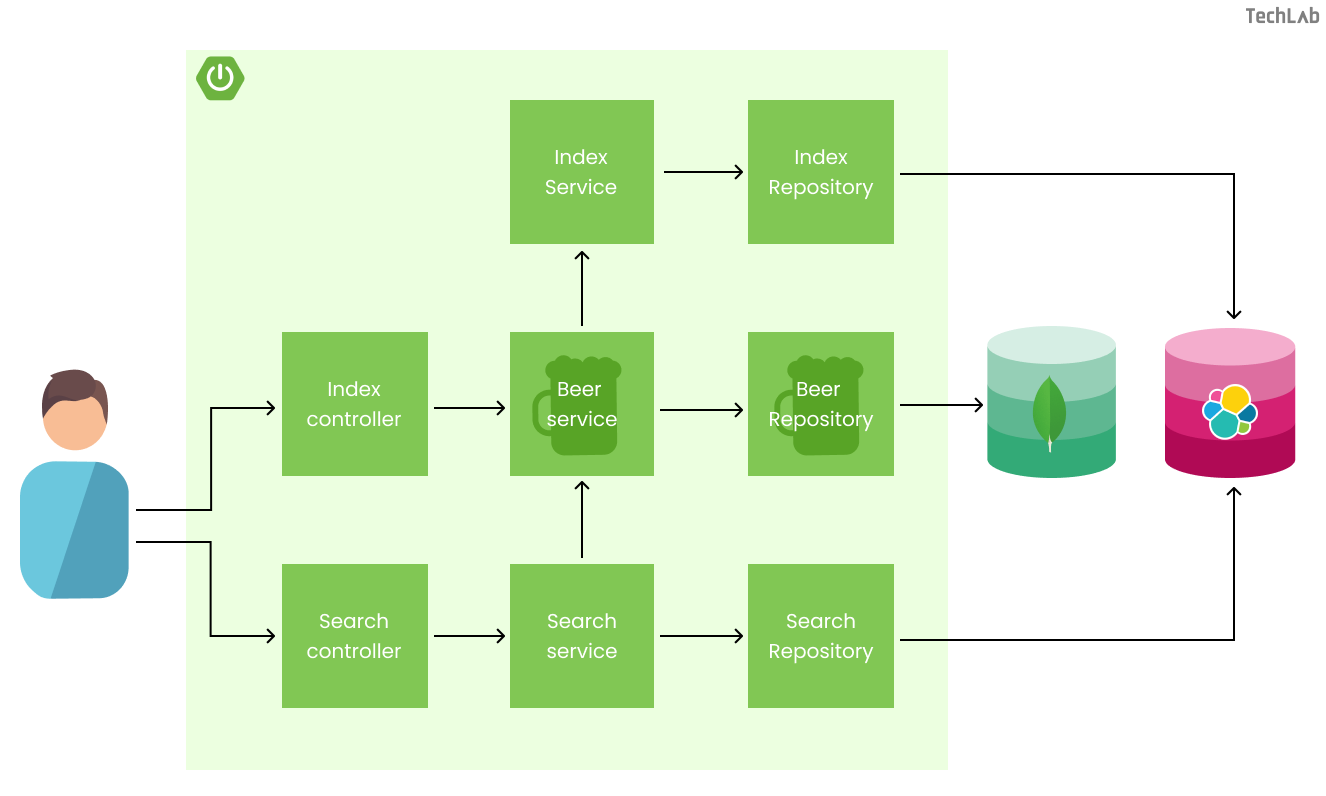
Voordat we kunnen zoeken naar informatieobjecten, moeten we eerst Elasticsearch configureren. Dit doen we door middel van een mapping. Als we een mapping hebben, kunnen we de zoekfunctionaliteit implementeren in onze API.
De Elasticsearch mapping beschrijft hoe een informatieobject opgeslagen en geïndexeerd moet worden. Dit doe je door middel van properties. In de onderstaande mapping zijn de id, type en exactTerms properties beschreven.
{
|
In de ID property wordt het MongoID opgeslagen dat door MongoDB gegeneerd is voor het object. Hiermee kunnen we voor alle zoekresultaten de originele objecten uit MongoDB ophalen. Keywords worden niet geanalyseerd door Elasticsearch, maar direct in zijn geheel geïndexeerd. Dit maakt de type property geschikt als filter, omdat er geen n-grams gemaakt worden en we een match op het volledige woord kunnen forceren.
Ten slotte is de exactTerms property gedefinieerd. Deze heeft het type "text" en wordt vóór het indexeren geanalyseerd. Hoe dit precies moet gebeuren staat beschreven in de custom analyzers. Deze zijn te vinden in elastic_analysis.json in de GitHub repository en komt neer op het volgende:
De meeste zoekopdrachten beginnen niet in het midden van een woord, dus de matches op de edge n-grams zijn belangrijker voor de uiteindelijke score van een zoekresultaat. De zoekopdracht "Hertog Jan" zal resulteren in de hieronder weergegeven n-grams en edge-ngrams.

Naast exactTerms bevat de mapping ook highPriorityTerms, midPriorityTerms en lowPriorityTerms voor de waardes met de hoogste, middelste en laagste prioriteit. Deze zijn precies hetzelfde gedefinieerd als de exactTerms en maken het mogelijk om de inhoud van informatieobjecten te prioriteren en dus een grotere invloed te geven in de uiteindelijke score van de resultaten.
Elasticsearch maakt gebruik van Apache Lucene voor het zoeken en gebruikt dus de Practical Scoring Function. Dit is een model gebaseerd op Term Frequency, Inverse Document Frequency en het vector space model. Als je meer wilt weten over de Practical Scoring Function kun je dit lezen in de Elasticsearch guide. Het belangrijkste om te weten is dat de scores gebaseerd zijn op hoe dicht een geïndexeerd object bij de opgegeven query ligt. Deze scores kunnen we beïnvloeden door een boost mee te geven aan delen van de query. Voordat een zoekopdracht naar Elasticsearch gestuurd wordt, splitst onze code de zoekopdracht op in meerdere queries per woord in de zoekopdracht. Dit proces is hieronder uitgeschreven en hierin wordt, door middel van regelnummers, verwezen naar de code onder de uitleg.
Een zoekopdracht wordt opgedeeld in meerdere kleine queries per woord in de zoekopdracht (regel 26 tot 48):
Deze drie queries worden uitgevoerd op de exactTerms, highPriorityTerms, midPriorityTerms en lowPriorityTerms velden. Afhankelijk van de prioriteit van het veld wordt er nog een offset toegevoegd aan de boost. Voor de exactTerms is dit 5 en dit gaat in stappen van 5 omlaag tot lowPriorityTerms die een offset heeft van -10.
Voor de zoekopdracht "Hert" zal dit resulteren in een query bestaande uit 12 kleinere queries (regel 58 tot 62) die samengevoegd worden tot één grote query:
De high-, mid- en lowPriorityTerms queries zijn fuzzyQueries.
Dit betekent dat de zoekopdracht niet helemaal overeen hoeft te komen, maar dat hier een bepaalde fout in mag zitten. Hiervoor wordt gebruikgemaakt van de Levenshteinafstand. De queries op exactTerms zijn niet fuzzy en moeten wel helemaal overeenkomen.
Een zoekopdracht bestaande uit drie woorden zal dus resulteren in een query bestaande uit 36 subqueries en voor elk woord in de zoekopdracht neemt dit met 12 subqueries toe.
class SearchRepository( |
Zoals ik aan het begin van deze blog beschreef, hebben we generieke velden in Elasticsearch gecombineerd met onze eigen annotation. Dit is de Searchable annotation.
@Target(AnnotationTarget.PROPERTY_GETTER) |
In hetzelfde bestand is ook de enum SearchField gedefinieerd die we eerder gezien hebben in de SearchRepository. Een waarde uit deze enum moet gekozen worden bij het gebruik van de Searchable annotation. Deze waardes komen overeen met de namen van de velden in Elasticsearch.
Omdat wij een slijterij hebben, willen we alleen drank indexeren. Hiervoor hebben we een superclass genaamd Drink gemaakt waar alle soorten drank van overerven. Door deze annotatie op de getters van een (subclass van) Drink class te zetten wordt het mogelijk om objecten hiervan te indexeren. Bijvoorbeeld de Beer class:
data class Beer( |
Van een Beer-object vinden we matches op de naam het belangrijkst, gevolgd door de stijl en tenslotte de ingrediënten. Ook moet het mogelijk zijn om te kunnen filteren door middel van het BEER type op regel 3. Voor de variatie hebben we ook een property waar we niet op willen zoeken, maar wel willen opslaan in MongoDB.
Een Drink subclass wordt uitgelezen en de waardes worden in een SearchObject gezet dat geïndexeerd kan worden. Dit gebeurt door middel van reflection in de IndexService.
private typealias PropertyToSearchable = Pair<KProperty1<out Drink, Any?>, Searchable> |
Op regels 30 tot 37 worden alle properties gelezen van de subclass van Drink. We zijn alleen geïnteresseerd in de properties met een Searchable annotation, dus deze filteren we eruit. Vervolgens worden er Pairs gemaakt van de property en de Searchable annotation.
De gevonden properties worden daarna gebruikt om de daadwerkelijke waardes uit te lezen van het Drink-object. Deze waardes worden gecast naar Lists van Strings en in een SearchObject gezet. De inhoud van de annotation bepaalt hier in welke property van SearchObject de waardes komen. Zo zullen de waardes van properties die geannoteerd zijn met Searchable(HIGH) in de highPriorityTerms van het SearchObject terechtkomen. Dit is terug te zien in regel 17 tot 24.
data class SearchObject( |
Om onnodige reflection te voorkomen bewaren we de resultaten van de getPropertyAnnotationsForClass functie zodat niet bij elk biertje opnieuw reflection toegepast moet worden voor het zoeken naar de annotations.
Nu bier geïndexeerd kan worden, kunnen we biertjes toevoegen en hiernaar zoeken. Voor het toevoegen van een biertje moet de naam, stijl, ingrediënten en het alcoholpercentage naar de IndexController gestuurd worden.
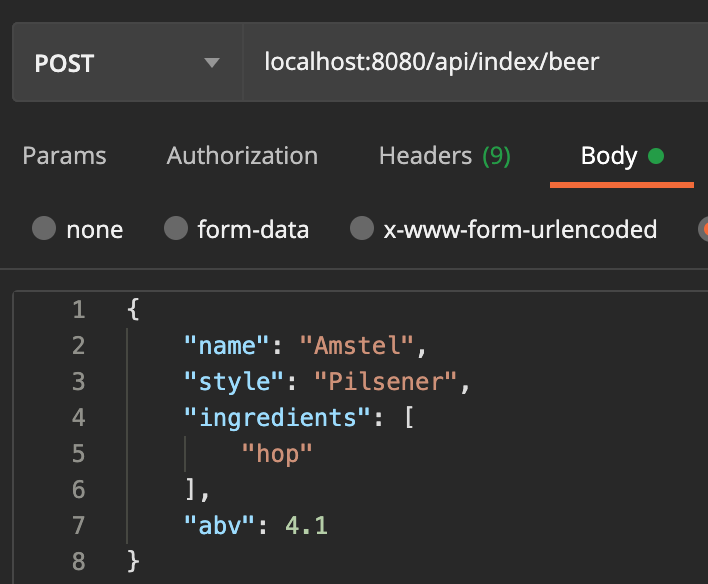
Na het toevoegen van een paar biertjes kunnen we gaan zoeken. Met de zoekopdracht "ams" en een beperking van de resultaten tot alleen bier verwacht ik dat de geïndexeerde Amstel bieren bovenaan staan.

[ |
De twee geïndexeerde Amstel-bieren staan inderdaad bovenaan in de resultaten. De Radler heeft een lagere score, omdat beide bieren gevonden zijn op basis van de naam en de naam van de Radler langer is en dus meer verschilt van de zoekopdracht. Het laatste biertje heeft een veel lagere score dan de eerste twee. Deze is dan ook niet gevonden op basis van de naam, maar waarschijnlijk op basis van "mais" in de ingrediënten. Door "ams" aan te passen naar "mas", wat ook direct de maximale toegestane Levenshteinafstand is, matched deze zoekopdracht op de edge n-gram "ma" van "mais". Door de maximale Levenshteinafstand en de lage boost op de ingrediënten krijgt dit resultaat een lage score ten opzichte van de andere resultaten.
Als je deze zoekfunctionaliteit in een frontend implementeert, kun je ervoor kiezen om resultaten onder een bepaalde score niet weer te geven op de frontend of überhaupt niet terug te geven vanaf de backend. Jupiler heeft hier zo'n lage score vergeleken met het gemiddelde dat je deze misschien niet wilt weergeven.
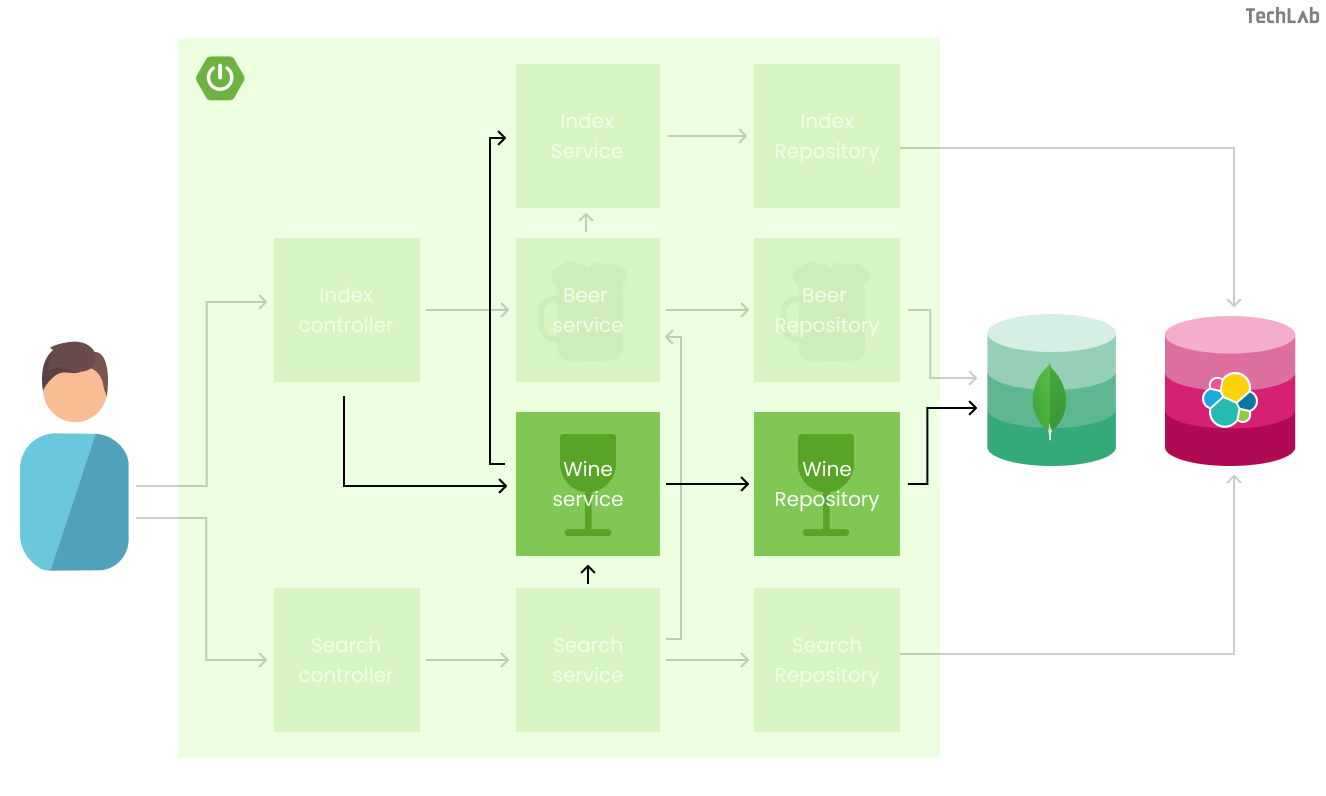
Door de manier waarop we Elasticsearch hebben ingericht in combinatie met de annotations, is het triviaal om nieuwe subclasses van Drink toe te voegen en te indexeren. We kunnen bijvoorbeeld wijn toevoegen aan onze zoekmachine, want niet iedereen houdt van bier. Hiervoor moeten de volgende wijzigingen aangebracht worden in de applicatie:
In de onderstaande afbeelding is weergegeven hoe het toevoegen van wijn de structuur van de applicatie aanpast. Naast de Beer service en repository komt hier een Wine service en repository.
 De Wine class komt grotendeels overeen met de Beer class, alleen willen we van wijn andere data opslaan dan van bier.
De Wine class komt grotendeels overeen met de Beer class, alleen willen we van wijn andere data opslaan dan van bier.
data class Wine( |
De WineRepository heeft geen extra functionaliteit nodig dan beschreven in de MongoRepositoryBase en de WineService is alleen een doorgeefluik aan de WineRepository en IndexService.
@Repository |
@Service |
Aan de IndexController moet, net zoals voor bier, een endpoint toegevoegd worden waarmee wijn toegevoegd kan worden. Deze moet het verzoek doorsturen naar de WineService.
@RestController |
Nu moet alleen nog de nieuwe wijn collection toegevoegd worden aan de MongoDB configuratie. Dit kan met de MongoCollections class.
@Configuration |
Na deze aanpassingen kan de applicatie opnieuw gebouwd worden en is het mogelijk om wijn te indexeren en te zoeken zonder de mapping van Elasticsearch aan te passen of te moeten herindexeren.
Het indexeren van wijn is bijna hetzelfde als het indexeren van bier. Stuur de naam, stijl, regio, druivenras(sen) en het alcoholpercentage naar het juiste endpoint in de IndexController.
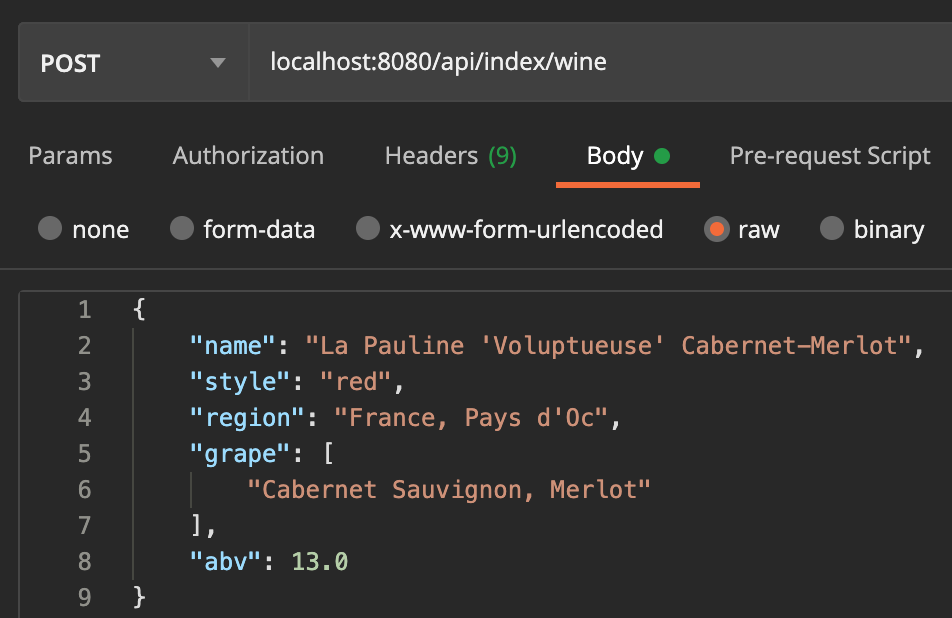
Nu we een wijntje hebben toegevoegd kunnen we deze gaan zoeken. Met de zoekopdracht "red" en geen beperking van de soorten drank verwacht ik dat de rode wijn bovenaan staat in de resultaten.

[ |
En dat is inderdaad het geval. De rode wijn heeft de hoogste score, omdat de zoekopdracht geheel overeenkomt met de stijl. De Amstel Radler scoort ook nog redelijk hoog, omdat "red" en "rad" bijna hetzelfde is, de match aan het begin van het woord is, de prioriteit van de naam van bier hoger is dan de stijl van wijn en het matcht op de naam en de stijl.
De broncode van de applicatie staat op GitHub. Deze repository bevat alle code om de applicatie te kunnen gebruiken. Ook staat hier een docker-compose en make bestand voor het opstarten van de applicatie. Verdere uitleg voor het gebruik van de applicatie is te vinden in de bijgeleverde README.
Als je in een applicatie gebruikmaakt van Elasticsearch wil je de mapping het liefst niet aanpassen, want een aanpassing in de mapping betekent vaak dat je alle data opnieuw moet indexeren. Dit probleem hebben wij deels opgelost door generieke velden te gebruiken in de mapping en deze velden te koppelen aan informatieobjecten door middel van een annotation. Hierdoor hoeft er niet opnieuw geïndexeerd te worden als je een nieuw soort informatieobject toevoegt en is het bovendien eenvoudig om nieuwe objecten te indexeren.
Voor deze oplossing zijn nog een aantal verbeteringen te bedenken. Zo is er bij een aanpassing van de annotations binnen een class, bijvoorbeeld een andere prioriteit of een nieuw veld, altijd een herindexatie vereist. Dit komt doordat de velden waarin wordt gezocht, gevuld worden op basis van de prioriteit in de annotation. Als je deze aanpast moet de inhoud van Elasticsearch ook bijgewerkt worden. In de huidige implementatie moeten Elasticsearch en MongoDB handmatig geleegd worden en alle objecten opnieuw toegevoegd worden via de index endpoints. Een verbetering zou zijn om een endpoint te maken voor het herindexeren. Deze moet de Elasticsearch data verwijderen en vervolgens de index opnieuw opbouwen door middel van de data die in MongoDB staat.
Een tweede verbetering is het toevoegen van configuratie in het scoresysteem. De huidige configuratie staat geheel beschreven in de code van de SearchRepository. Om hier aanpassingen in door te voeren moet de applicatie opnieuw gebouwd en gedeployed worden. Een eenvoudige verbetering zou hier al zijn om de verschillende boosts en offsets in een configuratiebestand te zetten. Hierdoor hoeft alleen de configuratie opnieuw geladen te worden wat zelfs zou kunnen zonder de applicatie opnieuw op te starten. Om de herbruikbaarheid van de queries te vergroten zou ook de inhoud via een configuratiebestand ingesteld kunnen worden. Hiermee kan bijvoorbeeld een deel van query weggelaten worden, zoals de query op n-grams, of de mate van fuzzy searching aangepast worden.
Je hebt nu genoeg aanknopingspunten om zelf aan de slag te gaan! Lees vooral de relevante stukken van de Elasticsearch guide als je meer wilt weten over de mapping, analyzers en queries die in de applicatie gebruikt worden. Deze guide is erg uitgebreid en zal een antwoord hebben op de meeste vragen.
| TechLab
Door Albert Veldman / okt 2024