Flexibel indexeren met custom Annotations voor Elasticsearch
Door Albert Veldman / sep 2021 / 1 Min

Door Marcel van Heerdt / / 8 min

In ons team werken we aan Phie, een softwareoplossing waarmee we informatie uit bestanden onttrekken en dat indexeren zodat het doorzoekbaar en groepeerbaar wordt. Dit kun je zien als een sequentieel proces van verwerkingsstappen: het begint met het onttrekken van allerlei verschillende gegevens, gevolgd door het indexeren daarvan. Je kunt je voorstellen dat het onttrekken van sommige gegevens afhankelijk is van een vorig bepaald gegeven, bijvoorbeeld het bepalen van de datum van een document op basis van de tekst die door middel van OCR is verkregen.
In een applicatie die het doel heeft om bewerkingen uit te voeren op een input (zoals een bestand in Phie) kun je tegen veel uitdagingen aanlopen. Wat doe je als er iets foutgaat in het proces? Hoe weet je in welk deel van het proces een input is? En hoe bepaal je of een actie wel of niet uitgevoerd moet worden op basis van de output van een vorige stap in het proces? Hoe kun je hele delen van het proces in- of uitschakelen voor een gebruiker of klant?
Deze vragen hadden wij ook toen wij op een flexibele manier bestanden wilden gaan verwerken. Dit moet flexibel gebeuren, omdat je bepaalde verwerkingsstappen niet voor alle soorten bestanden uit wil voeren. We willen bijvoorbeeld Optical Character Recognition uitvoeren om de tekst van documenten te bepalen, terwijl dat voor video's op een andere manier moet gebeuren. Een aantal verwerkingsstappen hoeft helemaal niet uitgevoerd te worden op de omgeving van bepaalde klanten.
Om deze uitdaging op te lossen hebben we onderzocht hoe je op een flexibele manier taken kunt uitvoeren in een soort pipeline. Een taak is hierbij iets wat uitgevoerd wordt voor een input. In deze blog vertel ik je waarom je een dergelijke architectuur nodig hebt, welke mogelijkheden je hebt en hoe je dit zelf kunt implementeren! Onderaan de blog vind je waar je de code die bij deze blog hoort kunt vinden.
Als je net als wij op een flexibele manier allerlei verschillende verwerkingsstappen uit wil voeren op een input, dan heb je een flexibele takenarchitectuur nodig. Door de taken helemaal vrijstaand te maken kun je ze onafhankelijk van elkaar schalen en configureren. Hierdoor worden ze ook beter onderhoudbaar en testbaar, omdat ze precies één stap in de verwerking uitvoeren.
Zoals ik in de inleiding heb verteld zijn er afhankelijkheden tussen taken, waardoor een graaf van taken ontstaat. Je hebt de keuze om handmatig de graaf van taken op te stellen door aan te geven welke taken bestaan en in welke volgorde deze uitgevoerd moeten worden. Het nadeel hiervan is dat er nog steeds een expliciete koppeling bestaat tussen taken. Als alternatief kun je ervoor kiezen om dit op een dynamischere manier op te lossen op basis van welke inputs en outputs de taken hebben, wat ik later in deze blog verder uitleg. Het nadeel hiervan is dat je minder controle hebt over de graaf.
Om aan de slag te gaan met een flexibele takenarchitectuur hebben we eerst gekeken naar bestaande oplossingen. De beste oplossing voor onze use-case bleek Apache Beam te zijn. Apache Beam is een programmeermodel om data processing pipelines op te stellen in code, waarna deze pipelines uitgevoerd kunnen worden op runners. Voorbeelden van deze runners zijn Apache Flink, Apache Spark en Google Cloud Dataflow.
Helaas sluit Apache Beam niet aan bij onze wensen. Naast dat we onze pipeline willen uitvoeren, hebben we ook wensen op het gebied van foutafhandeling en het gebruik van meerdere programmeertalen. Dit blijkt door Beam onvoldoende gefaciliteerd te worden, al wordt wel gewerkt aan het ondersteunen van meerdere programmeertalen in één pipeline. Op dit moment is dit alleen volledig beschikbaar voor de Python-SDK. De foutafhandeling is lastig, omdat je een hele set aan inputs fout moet laten gaan en die fouten niet eenvoudig zelf kunt afhandelen. Ook is de schaalbaarheid van bepaalde runners niet per taak in te stellen. Zo moet in theorie iedere machine iedere taak uit kunnen voeren, wat ervoor zorgt dat zelfs voor hele eenvoudige taken een krachtige machine gebruikt moet worden. Hoewel dit niet voor iedere runner geldt, is het limiterend voor de keuze die je hebt tussen runners.
Aan de hand van een casus vertel ik je hoe je een flexibele takenarchitectuur zelf op kunt zetten. In de casus wordt een vereenvoudigde versie van onze eigen architectuur gebruikt, zodat de focus ligt op de belangrijkste concepten. Het gebruik van een database en asynchrone messages is in de casus vervangen met in-memory opslag en synchrone aanroep van de taken. Het gebruik van asynchrone messages in een uitgebreidere architectuur, bijvoorbeeld door het gebruik van een message broker, zorgt ervoor dat niet gewacht hoeft te worden tot de taak klaar is.
Zoals je van eerdere blogs gewend bent, gaat de casus over het maken van verschillende soorten dranken. In deze applicatie maken we onderscheid tussen bier en wijn, omdat die met verschillende verwerkingsstappen worden gemaakt. Zo kan het maken van wijn bijvoorbeeld beginnen met het oogsten van druiven, waar het maken van bier begint bij het mouten van de gerst en het voorbereiden van de hop.
In onderstaande afbeelding zie je hoe deze verwerkingsstappen als taken in een graaf staan en beheerd worden door een "orchestrator". Deze orchestrator beheert welke taken uitgevoerd gaan worden voor een input. In het proces voor bier kun je zien dat de eerste twee taken parallel uitgevoerd worden en dat een latere taak indirect afhankelijk is van de output van deze beide taken.
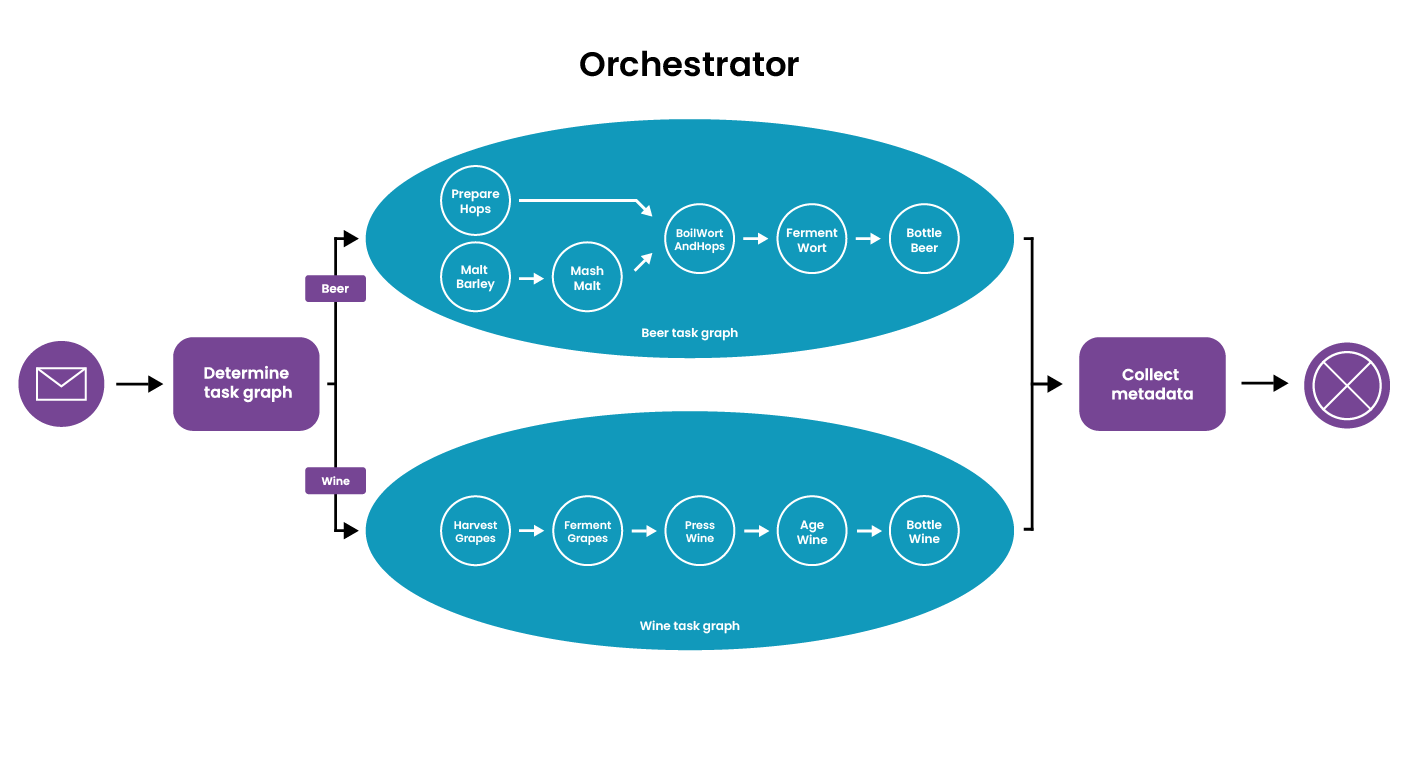
Om het maximale voordeel uit een flexibele takenarchitectuur te halen kun je het beste atomaire taken maken. Deze taken hebben precies één verantwoordelijkheid en zijn geoptimaliseerd om dat zo goed mogelijk uit te voeren. Uiteraard zal niet iedere actie een aparte taak worden. Zo zal het mouten van gerst ook het uitpakken van de ontvangen gerst bevatten, omdat dat niet iets is wat je tussen de taken door zou geven.
Een taak kan bepaalde inputs en outputs hebben, afhankelijk van wat de taak doet. Stel bijvoorbeeld dat je bij het bierbrouwproces een taak hebt voor het maischen van de mouten. Deze stap heeft bepaalde grondstoffen nodig, zoals de mout. Dit zijn de inputs voor de taak. Het resultaat van de stap is gemaischte mout, wat in een vervolgstap weer gebruikt kan worden. Dit is de output van de taak. In onderstaande afbeelding zie je dit weergegeven.
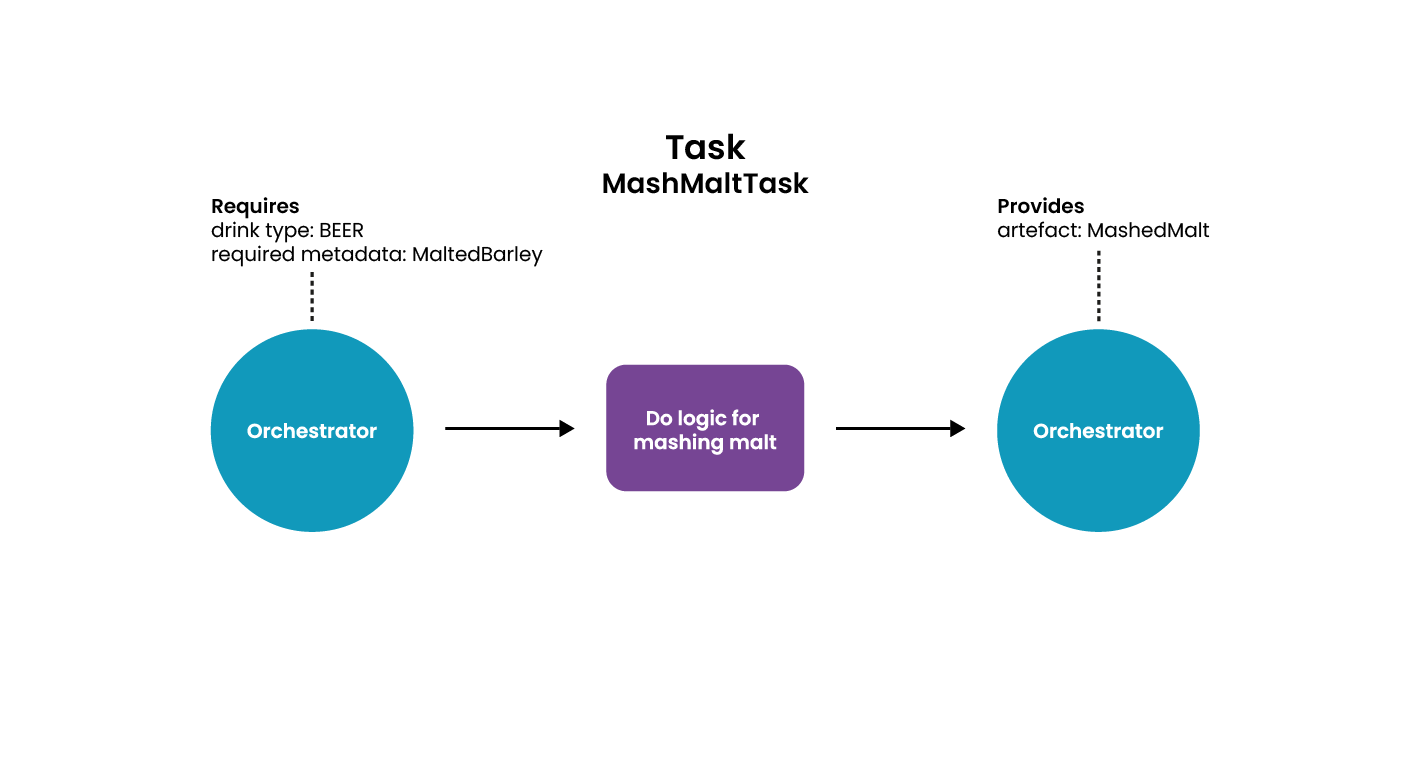 Deze taak wordt in twee delen geïmplementeerd: de taak zelf en informatie die de orchestrator nodig heeft voor het opbouwen van de graaf. De taak zelf is in het kader van deze blog ook geïmplementeerd in de orchestrator, waar je in een uitgebreidere versie deze als aparte service kunt deployen en via messages aan kunt spreken. Als de taak helemaal los staat van de rest van je code en aangesproken wordt via messages, maakt het niet meer uit welke programmeertaal je gebruikt voor de taak. Hiermee kun je dus meerdere programmeertalen gebruiken in één graaf van taken.
Deze taak wordt in twee delen geïmplementeerd: de taak zelf en informatie die de orchestrator nodig heeft voor het opbouwen van de graaf. De taak zelf is in het kader van deze blog ook geïmplementeerd in de orchestrator, waar je in een uitgebreidere versie deze als aparte service kunt deployen en via messages aan kunt spreken. Als de taak helemaal los staat van de rest van je code en aangesproken wordt via messages, maakt het niet meer uit welke programmeertaal je gebruikt voor de taak. Hiermee kun je dus meerdere programmeertalen gebruiken in één graaf van taken.
Een taak kan er uitzien zoals in onderstaand code-block staat. Bij asynchrone externe taken kun je, in plaats van de implementatie, een bericht versturen naar de externe taak. In dat geval zou je geen return-value geven en stuurt de externe taak een bericht terug wanneer die klaar is.
@Component
class MashMaltTask : Task(
taskId = "mash-malt",
supportedDrinkTypes = listOf(DrinkType.BEER),
requires = listOf(MaltedBarley::class),
produces = listOf(MashedMalt::class)
) {
override fun callTask(drinkId: String, inputData: List): List {
Thread.sleep(DEFAULT_SLEEP_TIME)
return listOf(MashedMalt(Random.nextLong(0, Long.MAX_VALUE)))
}
}
De gegevens die belangrijk zijn voor het opstellen van de graaf van taken worden als parameters meegegeven aan de constructor van Task. De taskId zorgt ervoor dat de taak geïdentificeerd kan worden, wat van belang is voor het bijhouden van de status van de taak voor een bepaalde input. De parameter supportedDrinkTypes geeft aan voor welke soorten drankjes de taak uitgevoerd kan worden. De laatste twee parameters, requires en produces, geven aan welke input(s) en output(s) de taak heeft. Deze gegevens zijn van belang voor het opbouwen van de graaf van taken en het aanleveren van de juiste gegevens aan de taak. De taak zelf doet in dit geval niets inhoudelijks, maar simuleert dit door een bepaalde tijd te wachten en dan de output MashedMalt terug te geven met een willekeurig ID.
Er zijn veel voordelen die je bij het introduceren van atomaire taken "cadeau" krijgt, die voortkomen uit de principes van high cohesion en low coupling. Het eerste voordeel is testbaarheid: omdat de taak precies één verantwoordelijkheid heeft en duidelijk gespecificeerd inputs en outputs heeft, kun je de taak goed testen. Het tweede voordeel is schaalbaarheid: omdat je je pipeline van verwerkingsstappen opsplitst in losse taken, kun je deze eenvoudig per taak schalen. Heb je bijvoorbeeld één hele zware taak die een bottleneck vormt voor de rest van de pipeline, dan kun je ervoor kiezen om alleen die taak verder op te schalen. Tot slot zorgt het introduceren van taken ervoor dat de begrijpbaarheid van je code verhoogd wordt. De naam van een taak kan precies aangeven welke logica zich in die taak bevindt.
Doordat de taken atomair zijn en alleen input/output leveren, moet er een ander gedeelte van het systeem zijn die de taken aanroept wanneer dat mogelijk is. Dit wordt gedaan door de orchestrator. Deze houdt bij welke outputs van vorige taken er zijn en bepaalt daarmee of alle gegevens beschikbaar zijn om een volgende taak uit te voeren.
Om de orchestrator te laten weten welke taken er zijn, kunnen verschillende strategieën gebruikt worden. De meest eenvoudige strategie is het opstellen van "connectoren" voor taken waarin aangegeven staan hoe de taak aangesproken kan worden, voor welke soorten input de taak geldt (bier of wijn) en welke inputs en outputs de taak heeft, zoals in de voorbeeldtaak in het vorige hoofdstuk. Het voordeel van deze strategie is dat de orchestrator exact weet welke taken er zijn en alle informatie daarvan heeft. Het nadeel is dat de orchestrator hiermee kennis moet hebben van alle taken en dat dus bij iedere nieuwe taak de orchestrator aangepast moet worden. In de vervolgstappen beschrijf ik een alternatieve strategie, waarmee je dit nadeel niet hebt.
Zodra de orchestrator toegang heeft tot alle beschikbare taken zal deze de verantwoordelijkheid hebben om de juiste taken te starten voor een drankje dat verwerkt wordt. In het geval van de casus zijn er twee mogelijkheden: het gaat om bier of het gaat om wijn. Dit kun je zien als twee aparte pipelines die gescheiden worden door het type drank. De orchestrator zal dus op basis van welke drank wordt aangevraagd de juiste taken moeten starten. In onderstaande code-block zie je hoe op basis van de huidige statussen van taken (STARTED, SUCCEEDED OF FAILED) de daaropvolgende taken worden opgehaald met de inputs die daarvoor nodig zijn. Hierna worden de nieuwe taken op STARTED gezet, gevolgd door het daadwerkelijk uitvoeren van de taken. Deze volgorde is gekozen vanwege het synchrone karakter van deze applicatie, zodat ook voor de vervolgtaken de status van de vorige taken bekend is.
private fun executeNextTasks(
drinkId: String,
type: DrinkType,
statuses: List
) {
val nextTasksWithInputs = taskService.getNextTasksWithInputArtefacts(drinkId, type, statuses)
nextTasksWithInputs.forEach { (task, _) -> taskService.startTask(drinkId, task.taskId) }
nextTasksWithInputs.forEach { (task, inputs) ->
executeTask(task, drinkId, type, inputs)
}
}
De functie getNextTasksWithInputArtefacts bepaalt op basis van de taakstatussen welke taken uitgevoerd kunnen worden. Hierbij wordt dus rekening gehouden met welke taken al zijn uitgevoerd, waardoor bekend is welke metadata beschikbaar is. Een taak waarvoor alle metadata beschikbaar is en die nog niet is gestart, wordt vervolgens gestart.
Zoals eerder genoemd heeft een taak bepaalde inputs. Op basis van welke inputs een taak heeft, kan bepaald worden of de taak voor het aangevraagde drankje uitgevoerd kan worden. De orchestrator houdt namelijk bij welke metadata er voor een aangevraagd drankje al beschikbaar is. Na iedere taak wordt deze metadata aangevuld met de output van die taak. In het volgende code-block zie je dat de nieuwe artefacts verwerkt worden bij het afronden van de taak, waarna opnieuw de functie executeNextTasks wordt aangeroepen. Het is namelijk mogelijk dat door de nieuwe artefacts een volgende taak uitgevoerd kan worden.
fun processNewArtefacts(
taskId: String,
drinkId: String,
type: DrinkType,
artefacts: List
) {
logger.info { "Completed task [$taskId] for drink [$drinkId], artefacts: [${artefacts.joinToString(", ") { it::class.simpleName ?: "" }}]" }
taskService.withCurrentStateOfDrink(drinkId) { statuses ->
if (statuses.none { it.taskId == taskId && it.drinkId == drinkId && it.status == Status.STARTED }) {
throw IllegalStateException("Cannot complete task that has not been started.")
}
val drink = drinkService.getDrink(drinkId) ?: throw IllegalStateException("Cannot get drink info")
val newStatus = taskService.completeTask(drink, taskId, artefacts)
val updatedStatuses = statuses.filter { it.taskId != taskId } + newStatus
executeNextTasks(drinkId = drinkId, type = type, statuses = updatedStatuses)
}
}
Een belangrijk aandachtspunt bij het draaien van meerdere instanties van de orchestrator is dat je wil voorkomen dat zij gelijktijdig dezelfde taak starten. Bij het gebruik van een database kun je bijvoorbeeld gebruik maken van een exclusieve lock op de TaskStatus-rijen van de input die op dat moment verwerkt wordt. Hierdoor zal de eerste instantie die weer iets met die specifieke input gaat doen een lock verkrijgen en de nieuwe taken starten. De andere instanties moeten wachten tot de lock weer is vrijgegeven en zien dan geen nieuwe taken om te starten.
Met de huidige opzet kunnen we taken flexibel opstellen en deze automatisch uit laten voeren in een graafvorm. Wel zien we nog enkele verbeteringen om de flexibiliteit te verbeteren en meer controle te geven over de uitvoer van de taken.
De eerste verbetering is het ondersteunen van conditionele taken. Stel dat je voor een biertje verschillende stijlen kunt bepalen en alleen voor de bierstijl "IPA" wil je een vervolgstap uitvoeren, namelijk het dry hoppen van het bier. Deze taak zou dan conditioneel moeten zijn op basis van de andere taak (bierstijl moet gelijk zijn aan "IPA"). Dit willen we toevoegen op een zo eenvoudig mogelijke manier voor de ontwikkelaar, het liefst in de taakdefinitie zoals eerder in deze blog besproken. Als ontwikkelaar wil je de waarde van een veld in een voorgaande output kunnen vergelijken met de waarde die het zou moeten zijn. Daarnaast wil je zowel AND-combinaties (alle condities moeten waar zijn) als OR-combinaties (één of meer van de condities moeten waar zijn) kunnen gebruiken.
Om beter inzicht te krijgen in welke taken er zijn en hoe een input door de graaf verwerkt wordt, is het wenselijk om de graaf in te kunnen zien. Door de afhankelijkheden tussen taken te gebruiken kan de graaf vooraf opgesteld en kunnen ook conditionele aftakkingen van de graaf in kaart gebracht worden. Het inzien van de graaf kan ons als ontwikkelaars helpen bij het verifiëren van een gekozen configuratie of bij het debuggen van fouten. Het kan ook inzicht geven aan een eindgebruiker als het gaat om de voortgang van de input in het proces.
Ook kan het voorkomen dat je (een deel van) de graaf opnieuw uit wil voeren. Dit kan bijvoorbeeld zijn omdat een taak fout is gegaan of omdat je een update voor een taak hebt doorgevoerd, waardoor je bepaalde inputs opnieuw wil verwerken. Door de status van alle volgende taken in de graaf te "invalideren" voor die input, kun je die taken nogmaals uitvoeren.
Daarnaast willen we ook configuratie toevoegen voor welke taken uitgevoerd moeten worden. Dit is relevant bij de deployment van de applicatie voor verschillende klanten die andere wensen hebben. De instanties van taken die uitgerold moeten worden en de taken die door de orchestrator worden opgenomen in de graaf moeten hiervoor geconfigureerd kunnen worden.
Tot slot is er de mogelijkheid om de informatie over de taak op te slaan bij de taak zelf in plaats van bij de orchestrator. Dan wordt de taak zelf verantwoordelijk voor wat hij kan doen in plaats van dat de orchestrator dat moet bijhouden. Een taak kan zich met zijn eigen gegevens "aanmelden" bij de orchestrator. Op deze manier hoeft de informatie over de taak niet bij de orchestrator te staan, maar kan iedere taak zelf beheren welke informatie bij die taak hoort. Door het aanmelden van de taak bij de orchestrator krijgt de orchestrator toch alle informatie die hij nodig heeft en is het mogelijk om de graaf van taken op te bouwen.
Door gebruik te maken van deze architectuur kun je ook zelf flexibel taken uit gaan voeren. Als je de informatie uit de blog combineert met de code-voorbeelden, heb je voldoende informatie om zelf een project op te zetten en naar eigen inzicht uit te breiden. De volledige code behorende bij de blog is beschikbaar via deze repository. In de readme vind je meer informatie over hoe je het project kunt gebruiken
| TechLab
Door Marcel van Heerdt / okt 2024