Problemen bij het trainen van face recognition-models. Zo los je ze op
Door Kevin Schomper / nov 2021 / 1 Min

Door Erik Evers / / 9 min

Wat als het trainen van een AI algoritme op je laptop niet meer gaat en oplossingen als Google AutoML niet toereikend zijn? Daarvoor hebben wij ons eigen Cloud-based AI Training Engine ontwikkeld!
Bij Avisi Labs doen we veel met Artificial Intelligence, van NER tot en met object detection. Het trainen van AI-modellen op je eigen laptop, dat is niet altijd ideaal. Data die gebruikt wordt voor het trainen komt verspreid terecht en als je ondertussen gewoon je werk wil doen, staat je laptop in de fik. Zodoende gingen we op onderzoek uit voor een betere oplossing dan het lokaal trainen van AI-modellen.
Ons doel:
Andere oplossingen, zoals Google AutoML, voldoen niet aan al deze eisen. Vandaar dat we onze eigen AI Training Engine hebben opgesteld. In deze blog nemen we je mee in welke stappen er zijn genomen om tot een eigen training engine te komen.
De Avisi Labs Training Engine gaat uit van het opstellen van een eigen trainingsscript. Dit kan een trainingsscript zijn voor verschillende doeleinden, zoals image classification of object detection. Het trainingsscript wordt uitgevoerd binnen een infrastructuur. Door Terraform te gebruiken, wordt de infrastructuur met Infrastructure as Code bij een cloud service opgezet.
De infrastructuur omvat een virtuele machine die het trainingsscript uitvoert met daaraan gekoppeld een GPU. Gedurende de training wordt, zoals gedefinieerd in het trainingsscript, output weggeschreven naar een outputmap. Deze map wordt bij het afronden van de training gedownload. Hierin staat het getrainde model. Bij het afronden van de training wordt de opgestelde infrastructuur weer afgebroken.
Op deze manier maak je een eigen AI training engine die geen grote investering vereist, waarbij je het model makkelijk kan aanpassen en snel kan bijsturen. Daarbij kan je, parallel aan het trainen, op de eigen computer blijven werken. Verder kan je een centrale opslagplek voor de gebruikte klantdata aanhouden, welke correct beveiligd is.
In dit onderdeel wordt ingegaan op de verschillende stappen die doorlopen worden bij het trainen van een AI-model met de Avisi Labs AI Training Engine. In figuur 1 is het gehele proces weergeven wat uitgevoerd wordt om een model te trainen met de AI Training Engine. Dit proces bestaat grofweg uit vier stappen: het opstellen van het trainingsproces, het opzetten van de infrastructuur, het uitvoeren van het trainingsproces op de opgezette infrastructuur en het afronden van dat proces. Per stap is aangegeven wat er opgesteld moet worden om die stap uit te kunnen voeren. Indien van toepassing, wordt aangegeven welke scripts in de stap uitgevoerd worden en wat door die scripts gebruikt wordt. Verder wordt aangegeven wat de output is van elke stap. In het vervolg van deze blog wordt apart ingegaan op de verschillende stappen uit het proces. Hier wordt verdere informatie gegeven over de op te stellen benodigdheden, wat er gebeurt bij het uitvoeren van de verschillende scripts en hoe dit leidt tot de verwachte output.
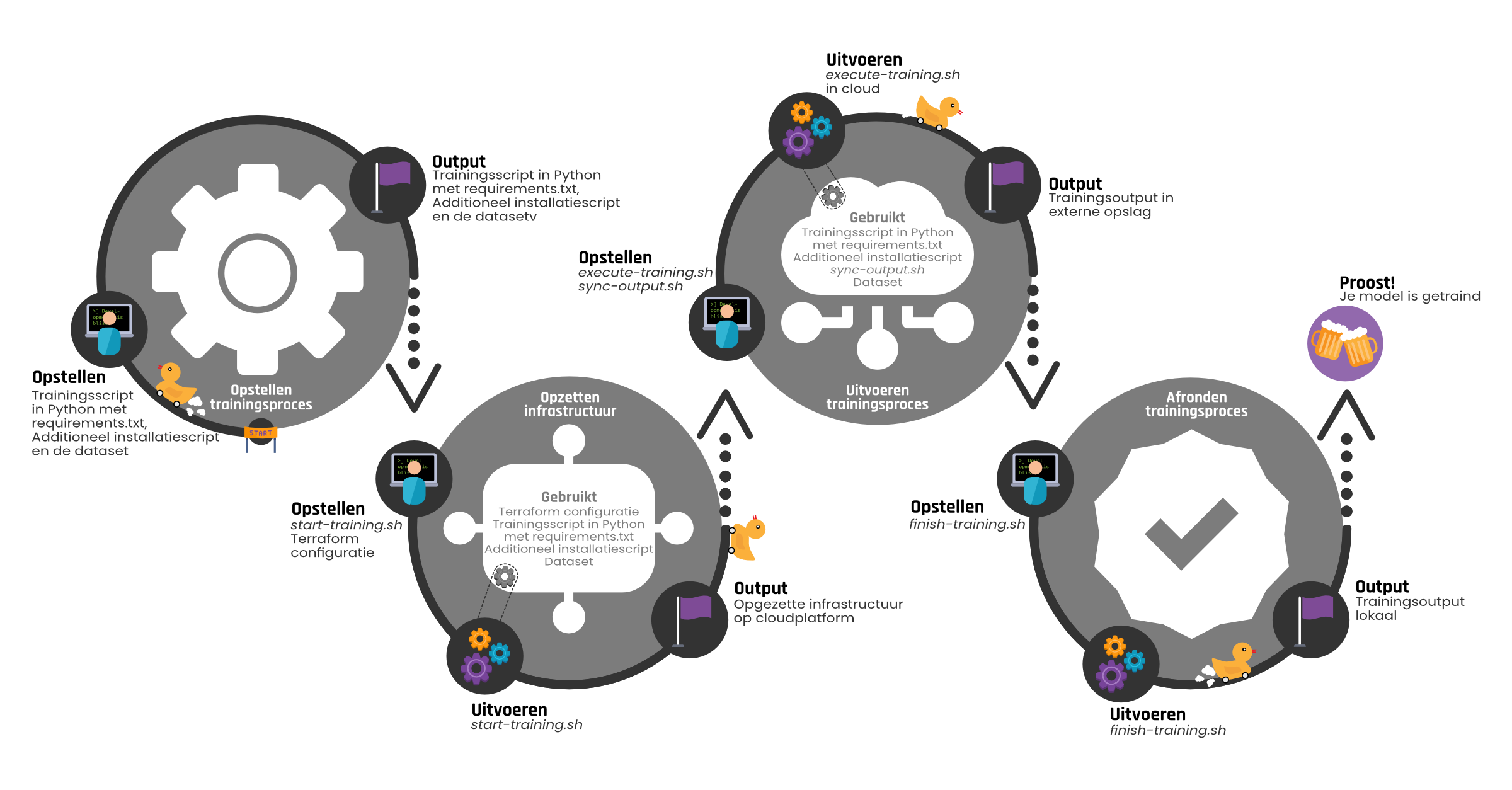
De eerste stap in het proces is het opstellen van het trainingsproces wat uitgevoerd wordt op de AI Training Engine. In figuur 2 is te zien welke onderdelen naar voren komen in deze stap.
Trainingsscript in Python
Om een AI-model te trainen met de AI Training Engine moet een trainingsscript opgesteld worden. Dit moet een Python-script zijn welke voldoet aan één enkele voorwaarde. Hij moet één main functie bevatten. Een voorbeeld hiervan is hieronder te zien:
from ai_training_utils.path_helper import PathHelper |
Binnen deze main functie ben je vrij om datgene uit te voeren wat nodig is voor het trainen van het AI-model. Denk hierbij aan het prepareren van data voor de training van het model of het opstellen van de layers die benodigd zijn voor een te trainen neuraal netwerk met Deep Learning. In bovenstaand voorbeeld is de aanroep te zien voor het trainen van een model voor image classification. Voorafgaand worden enkele acties uitgevoerd welke later toegelicht worden bij de Helper Libraries.
In een Python-script zal dikwijls gebruikgemaakt worden van externe dependencies. De dependencies worden samen met de benodigde versie vastgelegd in een bestand requirements.txt.
Met het Python-script zal een groot deel van de benodigdheden voor het trainen afgevangen worden. In sommige gevallen is echter meer configuratie vereist. Dit is lastiger te behalen in de vorm van een Python-script. Deze situatie kwamen wij zelf tegen bij het gebruik van de Object Detection API van Tensorflow. Om dit te installeren moeten verschillende commando's uitgevoerd worden. Dit kan beter gedaan worden in een bash-script dan in een Python-script. Om dit te ondersteunen is de mogelijkheid toegevoegd om een optioneel installatiescript op te stellen. Indien dit script aanwezig is, wordt deze uitgevoerd voordat het Python trainingsscript uitgevoerd wordt.
Het trainen van een AI-model zal voor een groot deel afhankelijk zijn van data die gebruikt wordt om te trainen. Hiervoor is het opstellen van een dataset vereist. De dataset wordt geplaatst in een externe opslag, zodat er een centrale plek is waar de data opgeslagen wordt. De data hoeft dan niet verdeeld te worden over verschillende ontwikkelomgevingen. Bij het uitvoeren van de training kan deze dataset gebruikt worden.
Zoals hiervoor besproken is, heeft data een groot aandeel in het trainen van een AI-model. Daarnaast is het van belang om tussentijds statistieken over de training te kunnen monitoren en te loggen. Ten slotte is het belangrijk om op het eind het getrainde model tot je beschikking te hebben. Om de benodigde data te kunnen bereiken en naar de correcte plekken data weg te kunnen schrijven, worden standaard drie argumenten meegegeven bij de aanroep van het opgestelde trainingsscript. Deze argumenten geven de paden aan naar verschillende mappen. In het voorbeeld hieronder is te zien dat de main methode uit de training module wordt aangeroepen, met daarbij de drie argumenten.
python -m "training_module.main" --dataset_directory /path/to/dataset --output_directory /path/to/output --logs_directory /path/to/logs |
De meegegeven argumenten bevatten de volgende relevante gegevens:
| Naam | Omschrijving |
|---|---|
| Dataset directory | Pad naar de directory met de bestanden die gebruikt worden om het model te trainen. |
| Output directory | Pad naar de directory waarin onder meer getrainde modellen weggeschreven kunnen worden. |
| Logs directory | Pad naar de directory waarin logbestanden weggeschreven kunnen worden. |
Verschillende acties die uitgevoerd moeten worden binnen een trainingsscript zullen repeterend zijn. In elk script wil je de mappen die meegegeven worden op een goede manier verwerken en beschikbaar maken. Verder zal je vaker een logger willen aanmaken die de logregels wegschrijft naar een bestand in de logs directory. Daarnaast zou je, mits er getraind wordt door gebruik te maken van TensorFlow, vaker gebruik willen maken van TensorBoard. Dit geeft inzicht in de huidige scores van het model dat getraind wordt. Om het dubbel implementeren van dergelijke logica te voorkomen, hebben wij enkele helper libraries opgesteld. Hieronder wordt weergeven welke libraries dit zijn en wat voor functionaliteiten deze libraries bieden.
| Naam | Omschrijving |
|---|---|
| PathHelper | Parseert de argumenten die meegegeven worden aan het trainingsscript en zorgt ervoor dat deze binnen een Singleton-klasse bewaard worden en verkrijgbaar zijn in andere onderdelen van het trainingsscript. |
| LoggingHelper | Logger, als Singleton, die logregels wegschrijft in een bestand binnen de logs directory die meegegeven is als argument aan het trainingsscript. |
| Monitoring | Functionaliteit voor monitoring, bijvoorbeeld voor het gebruik van TensorBoard of een andere monitoring tool. |
In het eerdere voorbeeld van het trainingsscript komen de PathHelper en TensorBoard terug. Op de lijnen zeven en acht wordt PathHelper aangemaakt en worden de meegegeven argumenten geparseerd. Op lijn 10 is te zien dat TensorBoard gestart wordt.
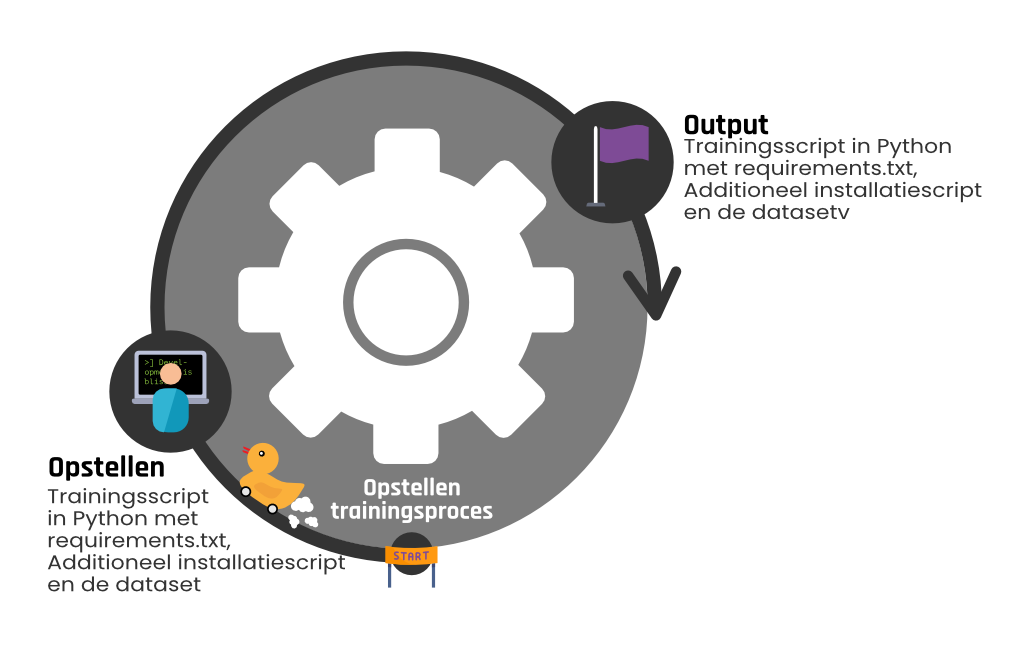
Nadat de benodigdheden zijn opgesteld voor het trainen in de vorm een trainingsscript en optioneel installatiescript, is het zaak om de infrastructuur voor de trainingsomgeving op te zetten waar deze scripts uitgevoerd worden. Dit is de tweede stap in het proces, deze wordt weergegeven in figuur 3. In het vervolg van deze blog zullen de voorbeelden gerelateerd zijn aan het gebruik van het Google Cloud Platform als cloud service.
Het opzetten van deze omgeving wordt geïnitieerd door lokaal een script uit te voeren waaraan verschillende argumenten meegegeven moeten worden:
./start-training.sh --project_name "project_name" --credentials_path "/path/to/credentials" --code_name "classifier" --code_path "/path/to/code/for/training" --dataset_name "beer" --dataset_bucket "training-dataset-beer" |
Hieronder wordt een omschrijving gegeven van de mee te geven argumenten.
| Argument | Omschrijving |
|---|---|
| project_name | Het specifieke project binnen Google Cloud Platform wat gebruikt wordt voor het opzetten van de resources. |
| credentials_path | Pad naar credentials voor authenticatie bij het Google Cloud Platform. |
| code_name | Naam voor de uit te voeren code bij het trainen, welke mede gebruikt wordt voor het uniek identificeren van het trainingsproces. |
| code_path | Pad naar de opgestelde code voor het trainingsproces. |
| dataset_name | Naam voor de te gebruiken dataset bij het trainen, welke mede gebruikt wordt voor het uniek identificeren van het trainingsproces. |
| dataset_bucket | Naam van Google Storage Bucket waarin de te gebruiken dataset is opgeslagen. |
Hierboven is aangegeven dat de codenaam en de datasetnaam gebruikt worden voor het uniek identificeren van het trainingsproces. Dit is nodig, omdat het met de huidige opzet van de AI Training Engine mogelijk is om meerdere trainingsprocessen parallel uit te voeren. Op basis van de meegegeven codenaam en datasetnaam zal het correcte trainingsproces benaderd worden indien meerdere trainingsprocessen worden uitgevoerd.
De omgeving wordt opgezet op basis van Infrastructure as Code. Dit is gedaan door gebruik te maken van Terraform. Middels Terraform kunnen definities opgesteld worden voor op te zetten resources bij een cloud service. In de huidige opzet hebben wij deze definities opgesteld voor het Google Cloud Platform. Deze zijn ook op te stellen voor andere bekende cloud services als Amazon en Azure. Hierdoor kan het trainingsproces op een platform naar keuze worden uitgevoerd.
Voor het trainen worden de volgende belangrijkste resources opgezet:
Aanvullend hierop zijn er enkele andere onderdelen die opgezet worden die per gebruikte cloud service zullen verschillen. Bijvoorbeeld de onderdelen die nodig zijn voor een firewall die ervoor zorgt dat de instance enkel via SSH te benaderen is.
Na het opzetten van de benodigde resources, waaronder de VM, worden de benodigde bestanden voor de training overgezet naar de VM. Allereerst worden verschillende mappen aangemaakt voor de code, de dataset, de output en de logs. Dit zijn de mappen die, zoals eerder benoemd, meegegeven worden aan het trainingsscript. Hierna wordt de code die gebruikt wordt voor het trainen uit de eerder benoemde bucket overgezet naar de VM. Hierop volgend wordt de dataset die gebruikt wordt voor het trainen van het model uit de externe opslag overgezet naar de VM.
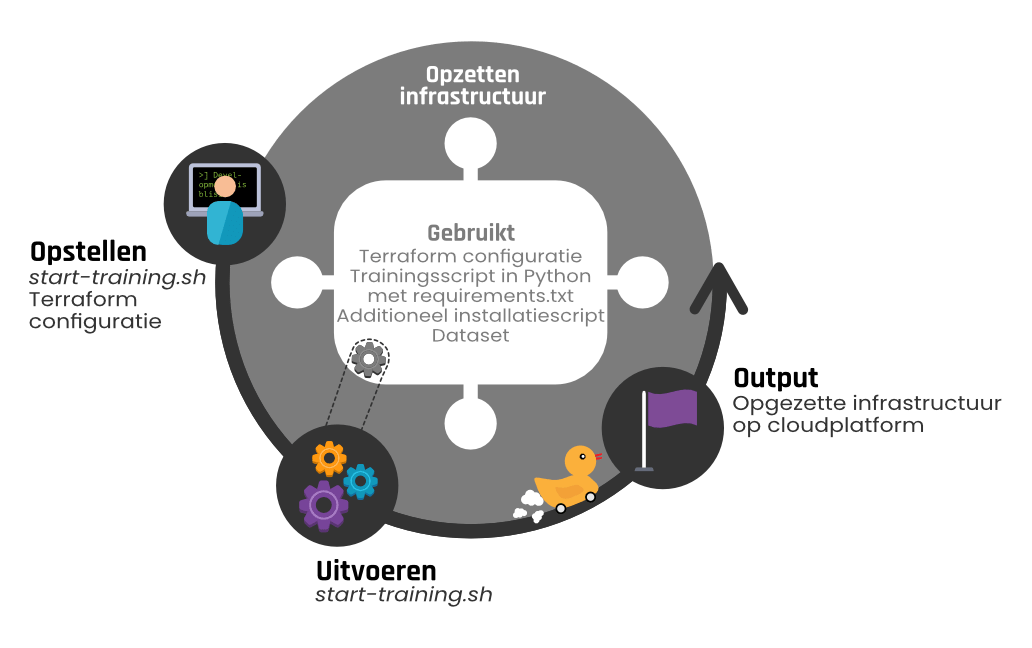
Nu alle benodigdheden zijn opgezet om de training op de VM uit te voeren, kan gestart worden met de training. Dit is de derde stap in het proces, welke weergegeven wordt in figuur 4.
Deze stap wordt uitgevoerd aan de hand van het script execute-training.sh. Deze is verantwoordelijk voor het starten van de synchronisatie van de output van de training. Daarnaast zorgt deze ervoor dat het trainingsproces correct gestart wordt op de VM.
Parallel aan het trainingsproces wordt een synchronisatie gestart voor het periodiek wegschrijven van de output van de training. Deze wordt weggeschreven naar de bucket die aangemaakt is voor het opslaan van deze output. Mocht het trainingsproces halverwege het proces foutlopen, dan is de output die tot dat moment is weggeschreven wel veiliggesteld. Bij gebruik van TensorFlow is het bijvoorbeeld mogelijk om model checkpoints op te slaan, waarbij het beste model op basis van de loss weggeschreven wordt. Door het synchroniseren van de output zal het meest recente model wat hierdoor is opgeslagen wel beschikbaar zijn.
Voor het trainingsproces worden eerst de benodigde dependencies geïnstalleerd op basis van de opgestelde requirements.txt. Hierna wordt, indien deze aanwezig is, het installatiescript uitgevoerd. Vervolgens wordt het eerder opgestelde trainingsscript uitgevoerd.
Nu het trainingsproces gestart is, is het belangrijk om te kunnen monitoren hoe het trainingsproces verloopt. De gemakkelijkste optie is om gedurende het proces meermaals de scores van het model te loggen. Met behulp van de eerdergenoemde LoggingHelper wordt dit weggeschreven naar een logbestand. Vervolgens kan dit bestand live meegelezen worden tijdens het uitvoeren van het trainingsproces. Daarnaast loont het om gedurende de training te controleren of de loss van het AI-model dat getraind wordt naar verwachting afneemt. Zoals eerder benoemd wordt bij TensorFlow vaak gebruikgemaakt van TensorBoard om onder andere de loss van het AI-model gedurende de training te monitoren. Deze wordt lokaal gestart op de VM. Om TensorBoard te kunnen benaderen starten we een port forwarding naar de juiste poort van de VM (6006 voor TensorBoard) door gebruik te maken van het externe IP-adres wat gekoppeld is aan de VM. Vervolgens is het mogelijk om lokaal TensorBoard op poort 6006 te benaderen. Hier is vervolgens live het trainingsproces te monitoren.
TensorBoard is één manier om de voortgang van de training te monitoren. Doordat het trainingsscript zelf opgesteld wordt, is het ook mogelijk om een andere wijze van monitoren toe te voegen bij het uitvoeren van de training.
Indien de uitvoer van het trainingsscript afgelopen is, wordt het periodiek synchroniseren van de output gestopt. Hierna wordt voor een laatste keer de output van het trainingsproces weggeschreven naar de eerder aangemaakte bucket. Vervolgens wordt de gebruikte VM afgesloten. Dit wordt gedaan om extra kosten voor een draaiende VM en gekoppelde GPU te voorkomen. Bij onder meer Google Cloud, Amazon en Azure worden geen kosten berekend voor niet-draaiende VM's. Wel worden er nog kosten berekend voor bijvoorbeeld de gekoppelde SDD.
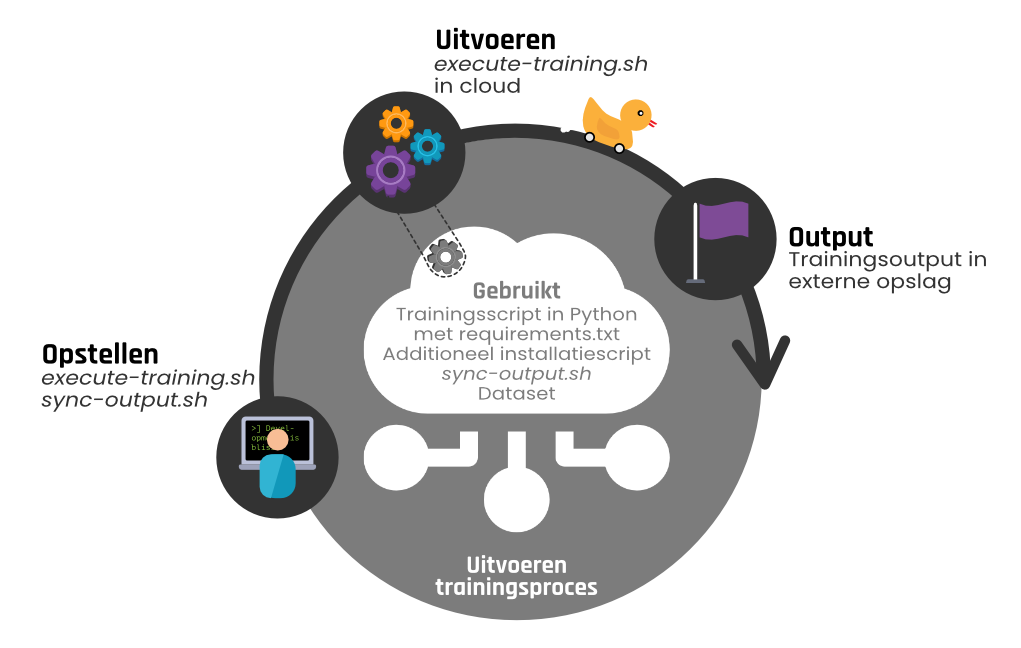
Nadat de training klaar is, is het belangrijk om de training af te ronden zodat de weggeschreven output lokaal opgeslagen wordt en de opgezette resources verwijderd worden. Deze laatste stap in het proces wordt weergegeven in figuur 5.
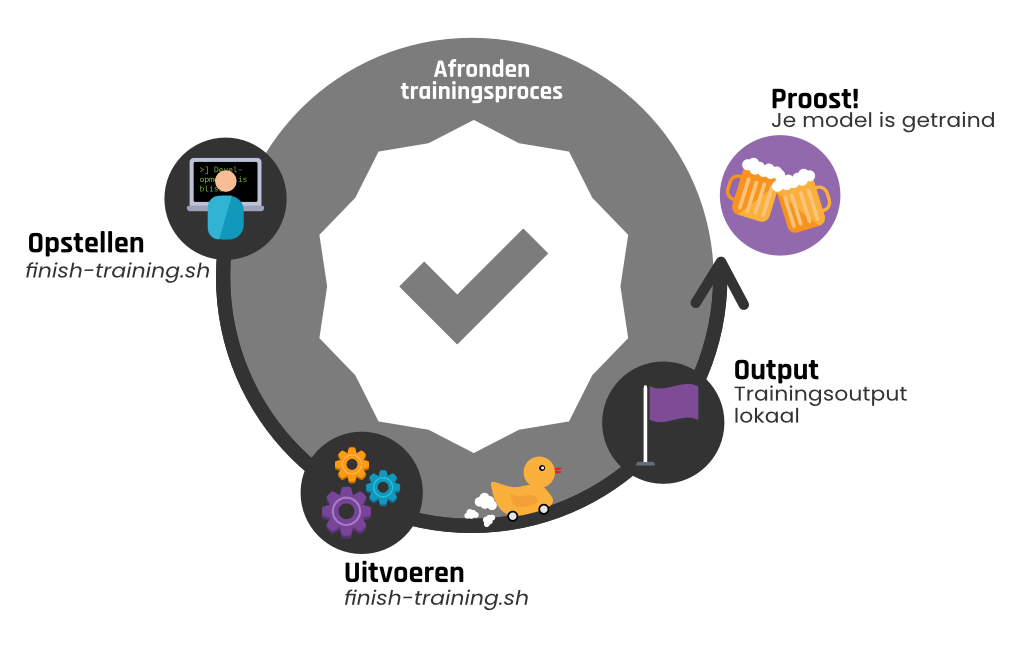
Het afronden van de training wordt gestart door een script aan te roepen met verschillende argumenten:
./finish-training.sh --project_name "project_name" --credentials_path "/path/to/credentials" --code_name "classifier" --dataset_name "beer" |
Hieronder wordt een omschrijving gegeven voor de mee te geven argumenten.
| Argument | Omschrijving |
|---|---|
| project_name | Het specifieke project binnen het Google Cloud Platform wat gebruikt wordt voor het opzetten van de resources. |
| credentials_path | Pad naar credentials voor authenticatie bij het Google Cloud Platform. |
| code_name | Naam voor de uit te voeren code bij het trainen, welke mede gebruikt wordt voor het uniek identificeren van het trainingsproces. |
| dataset_name | Naam voor de te gebruiken dataset bij het trainen, welke mede gebruikt wordt voor het uniek identificeren van het trainingsproces. |
Voor de argumenten geldt dat deze gelijk dienen te zijn aan de argumenten die meegegeven zijn bij het starten van de training.
Bij het uitvoeren van het trainingsproces is de output weggeschreven naar de externe opslag. Deze output wordt bij het afronden van de training gedownload, zodat deze lokaal beschikbaar is. De output wordt geplaatst in een map die voorzien wordt van een timestamp en waarin de codenaam en datasetnaam die meegegeven zijn als argument aan het commando zijn opgenomen. Hierdoor is lokaal te identificeren bij welk uitgevoerd trainingsproces de output hoort.
Op basis van de opgestelde definitie van de op te zetten resources met Terraform is het mogelijk om deze resources ook weer te verwijderen. Op deze wijze worden alle eerdergenoemde aangemaakte resources bij de cloud service verwijderd. Hiermee vervallen ook de kosten die betaald moeten worden aan de cloud provider voor bijvoorbeeld het externe IP-adres of de gebruikte opslag.
Na het lezen van deze blog heb jij de aanknopingspunten gekregen om zelf je eigen AI Training Engine op te stellen. Op deze wijze kan ook jij sneller en gemakkelijker je AI-modellen trainen!
| TechLab
Door Erik Evers / okt 2024