Deep Learning Neural Networks optimaliseren met Optuna
Door Albert Veldman / mrt 2022 / 1 Min
.jpg)
Door Kevin Schomper / / 12 min

Machine learning is hip en image recognition nog hipper; bijna iedereen die met een nieuwe smartphone werkt heeft er al mee te maken gehad. Een iPhone unlocken met face recognition of Google Photos die images categoriseert op personen en omgevingselementen. Of de auto's van Tesla die omgevingen in kaart brengt in een 3D weergave met behulp van zijn camera's image recognition. Wij bij Avisi hebben een blog geschreven over hoe je deze techniek zelf toe kunt passen in je bedrijf: Artificial Intelligence. Waar liggen jouw kansen?
In deze blog gaan wij focussen op een tak binnen de artificial intelligence: image recognition. Er zijn al veel artikelen geschreven over dit onderwerp en er zullen er nog velen volgen, maar wat opvalt is dat deze vaak een fictief probleem gebruiken met een prachtige dataset. In deze blog is er daarom voor gekozen om een model dat de Avisi Tech Lab leden identificeert te gebruiken. Dit model is gebaseerd op alle genomen foto's bij de fotoshoot van Avisi Tech Lab.
Wanneer je werkt met face recognition modellen kunnen er meerdere vragen naar voren komen, hiervan tackelt deze blog antwoorden voor de volgende:
Deze blog is op twee manieren te gebruiken: zoals andere blogs die je helpen om een eerste model te trainen (de complete code is hier beschikbaar voor het NN-model en het VGG-model: https://github.com/AvisiLabs/ATL-face-recognition) of voornamelijk waarvoor deze blog is geschreven; als inspiratiebron voor het identificeren van problemen waar jij mogelijk tegenaan loopt en een aantal oplossingen voor deze problemen.
Voor je begint met het opstellen van een image recognition-model is het belangrijk om te bepalen wat het doel is dat jij daarmee wil bereiken. Dit is in eerste instantie al belangrijk om te controleren of jouw model echt een probleem op probeert te lossen waarvoor je image recognition nodig hebt. Soms is het beter om een probleem op te lossen met normale programmacode, zoals bijvoorbeeld het automatisch bepalen van wanneer een lamp aan moet. Vervolgens geeft het doel van je model ook sturing aan hoe jij de dataset kan voorbereiden voor je model (een gezicht is belangrijkere data dan het lichaam als je een persoon wil identificeren).
Het doel van ons model is om de verschillende leden van het Avisi Tech Lab-team te kunnen identificeren op foto's. In dit geval is natuurlijk het belangrijkste element het gezicht, om personen te identificeren, al helemaal omdat wij meermaals hetzelfde Tech Lab-shirt dragen in de gebruikte dataset.
Dus eigenlijk zijn er twee subdoelen. Het herkennen van gezichten an sich en vervolgens het koppelen van deze gezichten aan leden van het Avisi Tech Lab-team.
We kunnen nu het doel van dit model vergelijken met het doel van andere image recognition-modellen. Zo is het doel van ons model hetzelfde als die van al bestaande face recognition-modellen, het identificeren van specifieke personen gebaseerd op hun gezicht. De context en specifieke categoriën zijn alleen anders. Dit betekent dat je deze modellen zou kunnen gebruiken als een basis voor je eigen model. Hier gaan we dieper op in bij transfer learning (kan je hiervoor een insite link gebruiken zodat hij naar de andere header gaat oid?).
Eerst kijken we naar hoe onze dataset eruitziet (deze splitsen we automatisch op in een training en validatieset later bij het genereren van een dataset). Er zijn twee soorten afbeeldingen: portretten met één persoon en groepsfoto's met twee tot drie personen. Hiervan zijn er in totaal 294 die bruikbaar zijn voor het model.
Verder valt meteen op dat de achtergrond constant hetzelfde is en dat er van het bovenlichaam foto's gemaakt zijn met verschillende kledingstukken, zoals hieronder in figuur 1 en 2 te zien is. Ten slotte is het ook belangrijk om een idee te hebben van de verdeling van de categorieën waarop je het model traint, zoals te zien in figuur 3. Zodat we deze verdeling mee kunnen nemen en hier mogelijk voor kunnen compenseren, bij het genereren van data.
 Figuur 1: Kevin met Tech Lab-shirt aan. Figuur 2: Kevin en Marcel
Figuur 1: Kevin met Tech Lab-shirt aan. Figuur 2: Kevin en Marcel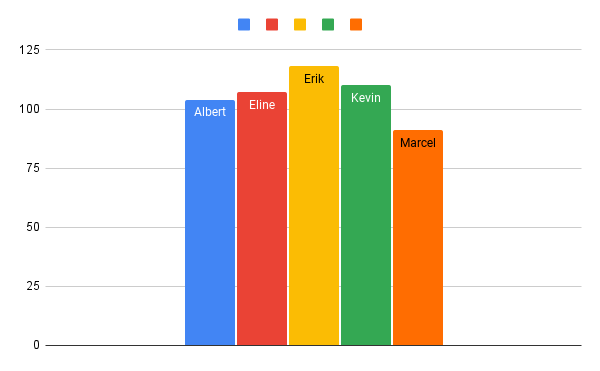
Figuur 3: in deze figuur is te zien hoe vaak verschillende personen aanwezig zijn in de dataset.
In een CSV-bestand is opgenomen welke personen aanwezig zijn op de verschillende afbeeldingen. Vervolgens kunnen we de CSV en de afbeeldingen inladen als de X en y voor ons model (X staat voor de input-data en y voor de labels die hieraan gekoppeld zijn).
import pandas as pd
import numpy as np
import glob
from tensorflow.keras.preprocessing import image
labels = pd.read_csv('AVL-Images - Sheet2.csv') # reading the csv file
print(labels.head()) # printing first five rows of the file
train_image = []
files = glob.glob('../images/*.jpg')
for file in files:
img = image.load_img(file,target_size=(256,256,3))
img = image.img_to_array(img)
img = img/255
img = img[..., ::-1]
train_image.append(img)
X = np.array(train_image)
y = np.array(labels.loc[:,['Albert', 'Eline', 'Erik', 'Kevin', 'Marcel']])
y.shape
Vanwege de manier waarop het VGG-Face model de dataset inleest, is hier een andere methodiek gebruikt voor het inladen van de dataset (uitleg over deze methodiek volgt in Transformaties voor VGG-Face).
from os import listdir
from os.path import isdir
from PIL import Image
from numpy import asarray, savez_compressed
FILENAME_DATASET = 'labs-dataset.npz'
FILENAME_FEATURE_VECTORS = 'labs-embeddings.npz'
def extract_face(filename, required_size=(224,224)):
img = Image.open(filename)
img = img.resize(required_size)
img_array = asarray(img)
return img_array
# load images and extract faces for all images in a directory
def load_faces(directory):
face_list = list()
for filename in listdir(directory):
if filename == '.DS_Store':
continue
path = directory + filename
face = extract_face(path)
face_list.append(face)
return face_list
# load a dataset that contains one subdir for each class that in turn contains images
def load_dataset(directory):
X, y = list(), list()
# enumerate folders, on per class
for subdir in listdir(directory):
path = directory + subdir + '/'
if not isdir(path):
continue
# load all faces in the subdirectory
faces = load_faces(path)
labels = [subdir for _ in range(len(faces))]
print('>loaded %d examples for class: %s' % (len(faces), subdir))
X.extend(faces)
y.extend(labels)
return asarray(X), asarray(y)
# load train dataset
train_X, train_y = load_dataset('faces/train/')
# load test dataset
test_X, test_y = load_dataset('faces/val/')
# save arrays to one file in compressed format
savez_compressed(FILENAME_DATASET, train_X, train_y, test_X, test_y)
De performance van een machine learning model is afhankelijk van de hoeveelheid data die beschikbaar is. Om ons model beter te laten presteren zullen wij daarom de initiele dataset uitbreiden aan de hand van transformaties. Er zijn veel verschillende transformaties mogelijk en om te meten welke het beste werken voor ons model zullen we verschillende transformaties toepassen e met elkaar vergelijken. De getrainde modellen gebruiken dezelfde architectuur (het eerste model in het hoofdstuk over architectuur); een neural network-model met convolutional en dense layers.
In figuur 4 is de accuraatheid van de validatie dataset vergeleken van de verschillende modellen. Deze modellen zijn op precies dezelfde manier getrained en gebruiken alleen een andere dataset. Hierin is nog niet voor elk model extra data gegenereerd en wordt de kwaliteit van het model bekeken met de getransformeerde trainingdata. Hierin is te zien dat modellen met een kleinere image input (256x256) meer succes hebben dan die met een grotere image input (400x400) en dat vormen van pixelbased normalisatie veel accuraatheid opleveren op de validatiedata (wat 10% is van de originele data). Het uiteindelijke NN-model is gebaseerd op het best presterende model, alleen dan met de dataset die we in het volgende hoofdstuk gaan genereren.
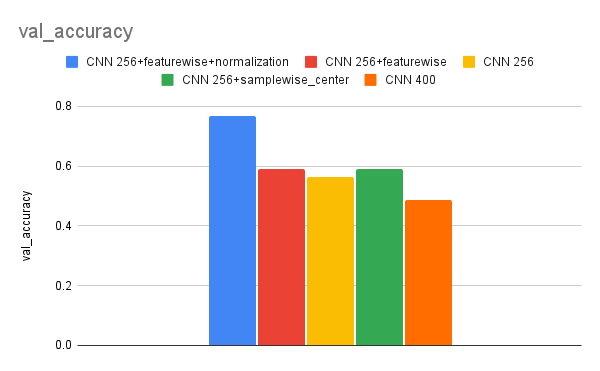
Figuur 4: de accuraatheid op de validatieset van de modellen gebaseerd op training met data transformaties
Om de modellen van meer data te voorzien is het mogelijk om de Keras-prepocessor te gebruiken, waarmee image transformaties worden uitgevoerd om nieuwe data te genereren.
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=30, test_size=0.1)
#Exact size of train_X to fill with data to extract in the following for loop.
fillable_X = np.zeros((264,256,256,3), dtype=np.float32) fudge_X_train = np.concatenate((X_train, dummy_dat), axis=3)
datagen_X = np.concatenate((train_X, fillable_X), axis=3)
datagen = image.ImageDataGenerator(featurewise_center=True, rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
datagen.fit(datagen_X)
X_batches = datagen_X
y_batches = train_y
epochs = 6
for e in range(epochs):
print('Epoch', e)
batches = 0
batch_size = 6
for X_batch, y_batch in datagen.flow(datagen_X, train_y, batch_size=batch_size):
X_batches = np.concatenate((X_batches, X_batch), axis = 0)
y_batches = np.concatenate((y_batches, y_batch), axis = 0)
batches += 1
if batches >= len(datagen_X) / batch_size:
break
#ImageDataGenerator adds another dimension that we don't need so we remove it.
train_X_new = X_batches[:,:,:,:3]
train_X_new.shape
Om een idee te geven van de gemaakte transformaties die deze code genereert volgen nu wat voorbeelden. In figuur 5 en 6 zijn voorbeelden te zien van transformaties die bij kunnen dragen aan het model. Zo is er gebruik gemaakt van het horizontaal flippen van de elementen en de illusie van diepte is op figuur 5 te zien door gebruik te maken van een shearing transformatie, verder is figuur 6 gedeeltelijk afgesneden tegenover de originele afbeelding. In figuur 7 is een voorbeeld te zien dat minder succesvol is uit de dataset, hierin is zoveel ingezoomd en gecropped dat Eline half uit de afbeelding verdwijnt, omdat deze data opnieuw annoteren veel tijd zou kosten is gekozen om het zoomen niet mee te nemen in de uiteindelijk gegenereerde dataset.
 Figuur 5, 6 en 7: Afbeeldingen met daarop meerdere soorten transformaties toegepast.
Figuur 5, 6 en 7: Afbeeldingen met daarop meerdere soorten transformaties toegepast.Er is een kleine ongelijkheid aanwezig in de data zoals te zien in figuur 3, Erik komt het meest voor en Marcel het minst. Dit zorgt in de praktijk voor een overfit op Erik en underfit op Marcel. Overfitten en underfitten zijn termen in machine learning die aangeven hoe goed het model de data begrijpt waarop hij getraind is en hoe goed hij data begrijpt buiten de trainingsdata. In het geval van overfitten begrijpt het model de trainingdata goed, maar niet meer data die niet aanwezig is in de trainingdata. Underfitten is wanneer het model de trainingdata en andere inputdata niet goed begrijpt.
Om voor deze ongelijkheiden te compenseren en de prestatie van het model te verbeteren is gebruik gemaakt van class weights. Class weights zorgen ervoor dat een model bepaalde classes kan prioriteren doordat er een hogere penalty gegeven wordt aan het model als deze een minder voorkomende class verkeerd classificeert. Hierdoor zal het model minder overfitten op Erik omdat hij minder afgerekend wordt op het incorrect predicten van Erik en zorgt er voor dat hij meer de focus legt op Marcel om hierop minder te underfitten.
De foto's in de originele dataset van de University of Oxford bevatten alleen het gezicht van de persoon. De rest uit de originele foto is weggesneden. Deze transformatie gaan wij ook toe passen op onze dataset. Dit is mogelijk door gebruik te maken van de DNN face detector. De code hieronder gebruikt het face detection model in, detecteert de verschillende gezichten en vervolgens worden de gezichten naar individuele afbeeldingen weggeschreven. Verder worden er geen transformaties uitgevoerd op onze dataset voor het VGG-Face model.
import cv2
import numpy as np
import os
from PIL import Image
model_file = "res10_300x300_ssd_iter_140000.caffemodel"
config_file = "deploy.prototxt.txt"
net = cv2.dnn.readNetFromCaffe(config_file, model_file)
images = os.listdir('images')
count = 0
for image in images:
if (image == '.DS_Store'):
continue
img = cv2.imread(os.path.join('images', image))
# img = cv2.resize(img, None, fx=2, fy=2)
height, width = img.shape[:2]
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# detect faces in the image
blob = cv2.dnn.blobFromImage(cv2.resize(img, (300, 300)),
1.0, (300, 300), (104.0, 117.0, 123.0))
net.setInput(blob)
faces = net.forward()
#OPENCV DNN
for i in range(faces.shape[2]):
confidence = faces[0, 0, i, 2]
if confidence > 0.5:
box = faces[0, 0, i, 3:7] * np.array([width, height, width, height])
face_img = Image.fromarray(box)
(x, y, x1, y1) = box.astype("int")
cv2.rectangle(img, (x, y), (x1, y1), (0, 0, 255), 2)
cv2.imwrite(os.path.join('faces', str(count) + '.jpg'), img[y:y1, x:x1])
count += 1
 Figuur 8: Uitgesneden gezicht Kevin
Figuur 8: Uitgesneden gezicht Kevin
train_X, train_y = load_dataset('../faces/train/')
test_X, test_y = load_dataset('../faces/val/')
data = load(FILENAME_FEATURE_VECTORS)
new_train_X, new_train_y, new_test_X, new_test_y = data['arr_0'], data['arr_1'], data['arr_2'], data['arr_3']
# normalize input vectors
in_encoder = Normalizer(norm='l2')
new_train_X = in_encoder.transform(new_train_X)
new_test_X = in_encoder.transform(new_test_X)
# label encode targets
out_encoder = LabelEncoder()
out_encoder.fit(train_y)
new_train_y = out_encoder.transform(new_train_y)
new_test_y = out_encoder.transform(new_test_y)
X = np.concatenate((new_train_X, new_test_X), axis=0)
y = np.concatenate((new_train_y, new_test_y), axis=0)
new_X = []
for i in X:
emb = np.zeros((1, 5))
i = expand_dims(i, axis=0)
emb[0,:] = model_svc.predict_proba(i)
new_X.append(emb)
new_X = asarray(new_X)
new_X = np.rollaxis(new_X,1,0)
new_X = new_X[0,:,:]
X = np.concatenate((train_X, test_X), axis=0)
plot_to_projector(X, new_X, asarray(y), ['Albert','Eline','Erik','Kevin','Marcel'])
Er zijn twee architecturen gebruikt voor onze machine learning modellen, beide zijn NN-modellen. Er zijn grote verschillen te zien tussen de architecturen, waarvan het belangrijkst is hoeveel meer complex de VGG-Facearchitectuur is (145,002,878 tegenover 1,356,133 trainbare parameters) en dat het VGG-Face model al meerdere keren is gebruikt buiten onderzoekskaders en zichzelf daarin heeft bewezen als een robuust accuraat model.
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=(5), activation="relu", input_shape=(256,256,3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=32, kernel_size=(5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(5), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu', name='intermediate'))
model.add(Dropout(0.5))
model.add(Dense(5, activation='softmax'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
from keras.layers import Convolution2D, ZeroPadding2D, MaxPooling2D, Flatten, Dropout, Activation
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(224,224, 3)))
model.add(Convolution2D(64, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Convolution2D(4096, (7, 7), activation='relu'))
model.add(Dropout(0.5))
model.add(Convolution2D(4096, (1, 1), activation='relu'))
model.add(Dropout(0.5))
model.add(Convolution2D(2622, (1, 1)))
model.add(Flatten())
model.add(Activation('softmax'))
model.compile()
Het VGG-Face model hierboven is al eerder getraind op 2.6 miljoen gezichten met 2622 identiteiten door de University of Oxford en het is uitermate succesvol in het identificeren van individuele gezichten (98.87% accuracy). De vraag is dan hoe is dit te gebruiken oms ons te identificeren? Er zijn twee methoden om het voorgetrainde model te gebruiken om ons te identificeren.
In beide methoden maak je in eerste instantie gebruik van de pretrained weights die beschikbaar zijn gesteld bij het VGG-Face model. Dat is mogelijk voor alle modellen als je de architectuur hebt om het model zelf te bouwen in Keras zoals hierboven en de pretrained weights. Dit is zo simpel als een functie aanroepen zoals hieronder is te zien.
model.load_weights('vgg_face_weights.h5')
Nu we de weights hebben ingeladen is het mogelijk om een model te bouwen bovenop het VGG-Face model om onze gezichten te identificeren. In de Keras documentatie staat aangegeven hoe je de layers kan bevriezen die nu getrained zijn en vervolgens nieuwe layers toe kan voegen om transfer learning toe te passen.
Heb je een model dat alleen uit te voeren is, dan is er nog steeds een manier om een soort "transfer learning" toe te passen. Om te laten zien hoe deze alternatieve methode kan worden gebruikt gaat deze blog daar verder op in.
We pakken de featurevectors van de laatste Convulation2D 2622 layer uit het VGG-Facemodel en vervolgens trainen we op deze featurevectors een SVC (Support Vector Classifier) model. Wat in de onderstaande codeblokken is te zien.
import numpy as np
from numpy import asarray, savez_compressed, load, expand_dims
def get_embedding(model, face_pixels):
# scale pixel values
face_pixels = face_pixels.astype('float32')
# standardize pixel values across channels (global)
mean, std = face_pixels.mean(), face_pixels.std()
face_pixels = (face_pixels - mean) / std
# transform face into one sample
sample = expand_dims(face_pixels, axis=0)
# make prediction to get embedding
yhat = model.predict(sample)
return yhat[0]
def load_compressed_dataset(path):
# Load a dataset with np.load with pickle enabled and then put the normal np.load back
# save np.load
np_load_old = np.load
# modify the default parameters of np.load
np.load = lambda *a,**k: np_load_old(*a, allow_pickle=True, **k)
data = load(path)
# putback the old load functionality
load = np_load_old
np.load = np_load_old
return data
data = load_compressed_dataset(FILENAME_DATASET)
train_X, train_y, test_X, test_y = data['arr_0'], data['arr_1'], data['arr_2'], data['arr_3']
print('Loaded: ', train_X.shape, train_y.shape, test_X.shape, test_y.shape)
# convert each face in train set to an embedding
new_train_X = list()
for face_pixels in train_X:
embedding = get_embedding(model, face_pixels)
new_train_X.append(embedding)
new_train_X = asarray(new_train_X)
# do the same for the test set
new_test_X = list()
for face_pixels in test_X:
embedding = get_embedding(model, face_pixels)
new_test_X.append(embedding)
new_test_X = asarray(new_test_X)
# save arrays to one file in compressed format
savez_compressed(FILENAME_FEATURE_VECTORS, new_train_X, train_y, new_test_X, test_y)
In het blok hierboven worden de featurevectors verkregen door een prediction uit te voeren met het VGG-Face model en deze worden vervolgens opgeslagen.
from numpy import asarray, savez_compressed, load, expand_dims
from sklearn.preprocessing import LabelEncoder, Normalizer
from sklearn.svm import SVC
# load faces
data = load(FILENAME_DATASET)
test_X_faces = data['arr_2']
# load face embeddings
data = load(FILENAME_FEATURE_VECTORS)
train_X, train_y, test_X, test_y = data['arr_0'], data['arr_1'], data['arr_2'], data['arr_3']
# normalize input vectors
in_encoder = Normalizer(norm='l2')
train_X = in_encoder.transform(train_X)
print(train_X.shape)
test_X = in_encoder.transform(test_X)
# label encode targets
out_encoder = LabelEncoder()
out_encoder.fit(train_y)
train_y = out_encoder.transform(train_y)
test_y = out_encoder.transform(test_y)
# fit model
model_svc = SVC(kernel='linear', probability=True, C=3)
model_svc.fit(train_X, train_y)
In het codeblok hierboven wordt een Liniear SVC model getrained op de featurevectors. Dit is een veelgebruikte model omdat dit effectief is in het sepereren van genormalizeerde face embedding input. Ook wordt er in de code nog wat voorbewerking gedaan op de dataset om aan deze normalisatie te komen (met gebruik van de Normalizer van Scikit-learn).
Om inzicht te krijgen in de prestatie van deze modellen, zijn verschillende methodes beschikbaar. Dit kan al door de accuraatheid van de testset op te vragen. Door de featurevectors in een projectie te weergeven, kunnen inzichten worden opgedaan.
In de bijbehorende video, laten we zien hoe je een projector gebruikt. Hiermee kan je inzien welke categorieën dicht bij elkaar liggen en waarom.
Om de projector te gebruiken, moet je een export hebben van de featurevectors ven het model. Deze worden ingelezen door Tensorboard samen met een sprite (wat een NxN grootte representatie is van alle afbeeldingen in de dataset te zien in figuur 8) die met een metadata-bestand de featurevectors labelt.
import os
import shutil
from tensorboard.plugins import projector
import tensorflow as tf
def plot_to_projector(
x,
feature_vector,
y,
class_names,
log_dir="logsVGG",
meta_file="metadata.tsv",
):
assert x.ndim == 4 # (BATCH, H, W, C)
if os.path.isdir(log_dir):
shutil.rmtree(log_dir)
# Create a new clean fresh folder :)
os.mkdir(log_dir)
# Create sprite
sprites_file = os.path.join(log_dir, "sprites.png")
sprite_x = x*255
sprite = create_sprite(sprite_x)
img = Image.fromarray(sprite)
img.save(sprites_file)
# Generate label names
labels = []
for i in range(int(y.shape[0])):
labels.append([])
labels[i].append(class_names[y[i]])
# Save metadata file
with open(os.path.join(log_dir, meta_file), "w") as f:
for label in labels:
f.write("{}\n".format(label))
if feature_vector.ndim != 2:
print(
"NOTE: Feature vector is not of form (BATCH, FEATURES)"
" reshaping to try and get it to this form!"
)
feature_vector = tf.reshape(feature_vector, [feature_vector.shape[0], -1])
print(feature_vector.shape)
# Save feature embeddings
feature_vector = tf.Variable(feature_vector)
checkpoint = tf.train.Checkpoint(embedding=feature_vector)
checkpoint.save(os.path.join(log_dir, "embeddings.ckpt"))
# Set up config
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = meta_file
embedding.sprite.image_path = "sprites.png"
embedding.sprite.single_image_dim.extend((x.shape[1], x.shape[2]))
projector.visualize_embeddings(log_dir, config)
In de functie hierboven gebeurt veel, de belangrijkste handelingen zijn (in de volgorde van het script):
def create_sprite(data):
"""Creates the sprite image along with any necessary padding
Args:
data: NxHxW[x3] tensor containing the images.
Returns:
data: Properly shaped HxWx3 image with any necessary padding.
"""
if len(data.shape) == 3:
data = np.tile(data[...,np.newaxis], (1,1,1,3))
data = data.astype(np.float32)
min = np.min(data.reshape((data.shape[0], -1)), axis=1)
data = (data.transpose(1,2,3,0) - min).transpose(3,0,1,2)
max = np.max(data.reshape((data.shape[0], -1)), axis=1)
data = (data.transpose(1,2,3,0) / max).transpose(3,0,1,2)
data = 1 - data
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = ((0, n ** 2 - data.shape[0]), (0, 0),
(0, 0)) + ((0, 0),) * (data.ndim - 3)
data = np.pad(data, padding, mode='constant',
constant_values=0)
# Tile the individual thumbnails into an image.
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3)
+ tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
data = (data * 255).astype(np.uint8)
return data
Hierboven staat de code voor het creëren van een sprite, hierin worden een aantal transposities gedaan om een NxN sprite plaatje te maken. Deze sprite wordt vervolgens in Tensorboard opgesneden zodat elke individuele afbeelding gekoppeld is aan een datapunt. Wat een sprite oplevert zoals te zien in figuur 8.
 Figuur 9: een sprite met daarin een onderdeel van de MNIST dataset.
Figuur 9: een sprite met daarin een onderdeel van de MNIST dataset.
train_X, train_y = load_dataset('../faces/train/')
test_X, test_y = load_dataset('../faces/val/')
data = load(FILENAME_FEATURE_VECTORS)
new_train_X, new_train_y, new_test_X, new_test_y = data['arr_0'], data['arr_1'], data['arr_2'], data['arr_3']
# normalize input vectors
in_encoder = Normalizer(norm='l2')
new_train_X = in_encoder.transform(new_train_X)
new_test_X = in_encoder.transform(new_test_X)
# label encode targets
out_encoder = LabelEncoder()
out_encoder.fit(train_y)
new_train_y = out_encoder.transform(new_train_y)
new_test_y = out_encoder.transform(new_test_y)
X = np.concatenate((new_train_X, new_test_X), axis=0)
y = np.concatenate((new_train_y, new_test_y), axis=0)
new_X = []
for i in X:
emb = np.zeros((1, 5))
i = expand_dims(i, axis=0)
emb[0,:] = model_svc.predict_proba(i)
new_X.append(emb)
new_X = asarray(new_X)
new_X = np.rollaxis(new_X,1,0)
new_X = new_X[0,:,:]
X = np.concatenate((train_X, test_X), axis=0)
plot_to_projector(X, new_X, asarray(y), ['Albert','Eline','Erik','Kevin','Marcel'])
Tenslotte worden alle afbeeldingen nogmaals ingeladen en voorbereid om in de projector-functie in te laden. Deze projector kan opgestart worden met het inladen van de logdirectory in Tensorboard via het volgende commando:
tensorboard --logdir path/to/your/log
Samenvatting
Nu zie je een 3D-projectie ingeladen worden van jouw model, waarin de featurevectors toegepast zijn op de dataset. Er zijn duidelijke groepen gevormd in de data. Hierdoor zijn mogelijke overlappingen logisch te redeneren. Dit helpt jou verder in het begrijpen van de voorspellingen van je model. In de projector voor de Tech Lab-dataset is goed te zien dat Erik en Marcel goed te identificeren zijn en niet overlappen met de andere categorieën. Kevin en Albert hebben wel veel overlap, vooral wanneer Kevin ook een bril draagt, wat mogelijk betekent dat het model de bril een erg belangrijke feature vindt.
Hopelijk heb je nu inzicht in het trainen van een image recognition model en kan jij veelvoorkomende problemen oplossen. De belangrijkste punten van deze blog vat ik hieronder samen:
Door het doel van het model scherp te definiëren, is het makkelijker om de dataset voor te bereiden voor je model. Ik raad het aan om het model van tevoren te kiezen, omdat dit invloed heeft op de voor te bereiden dataset. Door data te genereren gebaseerd op de originele data is het mogelijk om met een kleinere dataset je model alsnog beter te laten presteren.
De toepassing van transfer learning kan compenseren voor een mindere hoeveelheid data en een kickstart geven aan jouw model. Tot slot heb je nu een script, waarmee je een projector met metadata op kan zetten voor jouw model. Dit kan je gebruiken om de groeperingen te zien die het model gerealiseerd heeft.
Wil je nog meer lezen over dit onderwerp of de Github bekijken om zelf een omgeving op te zetten? Lees dan onderstaande links.
De Github-repositorie die bij dit project hoort is hier te vinden: https://github.com/AvisiLabs/ATL-face-recognition. In deze repo staan nog wat tests opgenomen, die het model testen op data buiten de dataset door nieuwe afbeeldingen in te laden. Ook staat er een helperscript in om alle gezichten uit de originele images te halen.
Transfer learning op de normale manier toepassen is uitvoerig beschreven in de Keras documentatie en interessant als dat beter aansluit bij jouw use case: https://keras.io/guides/transfer_learning/.
Geïnteresseerd in andere hoge kwaliteit image recognition voorbeelden en tutorials? Kijk ook eens hier: https://github.com/serengil/tensorflow-101
| Artificial Intelligence
Door Kevin Schomper / okt 2024